


最近读完了《贪婪的多巴胺》,这本书从脑科学视角解释了人类行为背后的驱动力。而在阅读过程中,我不断联想到之前在《伯努利的谬误》中提到的贝叶斯推理,以及将认知科学和人工智能结合起来的《Bayesian Models of Cognition》。这三本书看似毫不相干——一本是讲多巴胺在大脑中的工作原理(为了面向大众读者,做了很多简化,语言比较通俗易懂)以及多巴胺跟社会现象的种种关系,一本讲概率统计,频率学派和贝叶斯学派的两三百年之争,以及如何利用贝叶斯定理去构建模型,去模拟人类的推理过程——但我发现它们指向了同一个深刻的问题:人类大脑的运转,一方面在面对很多的选择的时候,需要使用基于概率的推理框架来做因果推理;另一方面,还需要有一套感觉系统,该系统将视觉,听觉和触觉等原始信号综合起来,结合时间和空间信息,变为了感觉,感觉再经过某种结构,固化为了知觉或者叫经验,从输出动作的角度来看,知觉应该是上面的第一方面的部分,类似一个打分系统,这一部分更像一个行动系统,行动系统根据打分系统的输出去采取行动。因果推理会在不断学习过程中做抽象,学习到的知识会用于打分系统,最终都是服务于行动的输出。在这里,不得不提到杨立昆的世界模型,他提出的 JEPA(Joint Embedding Predictive Architecture)模型,正是试图还原大脑做推理和决策的机制,提出一种具有自主智能的模型结构。这个构想非常类似于人脑的工作流程,可以为机器智能提供非常好的架构指导。
多巴胺:一个"可能性"的信徒
《贪婪的多巴胺》最核心的观点是:多巴胺并非"快乐分子",而是"欲望分子"。它不负责让你享受当下,而是驱使你追逐未来。它最大的作用是将我们对未来的的想象这种偏图景化的东西,转化为去寻找或者实现的动力。
澳大利亚神经科学家约翰·佩蒂格鲁(John Douglas Pettigrew)发现了一个关键事实:大脑将外部世界分为两个独立的区域来管理——“近体的"和"远体的”。 “近体”体现在当下的体验或者触手可及的空间,“远体”体现在未来的可能性或者伸手无法到达的空间。
多巴胺专注于远体空间,专注于"还没有到手的东西"。
多巴胺有一个非常特殊的职责:最大化利用未来的资源,追求更好的事物。
这意味着什么?多巴胺本质上是在做一件事:对未来的可能性下注。 它不关心你已经拥有的,只关心你可能获得的。这就是为什么赌博让人上瘾,为什么热恋会让人疯狂,为什么艺术家永远不会对已完成的作品满足。
但问题在于,大脑对"可能性"的评估,往往是有偏差的。或者说,对未来可能性的评估,并不是多巴胺要做的事情,专门有系统负责评估,本书并没有提及该系统的细节。
多巴胺产生的原因:奖赏预测误差与TD误差
研究这个现象的科学家把这种从新奇事物中得到的快感命名为“奖赏预测误差”。我们每时每刻都在预测将要发生的事,从什么时候可以下班,到在自动取款机上看到卡里有多少余额。实际发生的事好于我们的预期,就表明我们对未来的预言存在误差:可能我们可以提前下班了,或者查看余额时发现比预期多了100元。正是这种让人快乐的误差触发多巴胺行动起来。这种快乐不是源于额外的时间或钱本身,而是预期之外的好消息带来的兴奋感。
这恰恰就是强化学习中时序差分误差(TD Error)的定义:
$$\delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)$$
其中 $V(s_t)$ 是大脑对当前状态的预期价值,$r_t + \gamma V(s_{t+1})$ 被看作是实际获得的奖励加上对未来价值的估计($V(s_{t+1})$其实不一定准确)。当实际情况好于预期,$\delta_t > 0$,多巴胺爆发——这与神经科学实验中观察到的多巴胺神经元放电模式完全一致。如果某种信号用来指导行动的话,那就是更一般的形式,强化学习中的优势函数 $A(s,a) = Q(s,a) - V(s)$ 度量的是某个具体行动比"平均表现"好多少,它几乎是最低方差的策略梯度估计。多巴胺系统在做的事情,本质上是计算优势函数——将预期与现实的差距转化为行动的动力。
我自己的观点:
大脑中有一个区域负责预测未来的状态,这个区域会根据当前的状态、你采取的行动和过去的经验,生成一个对未来的预测,这个预测不仅仅是将来要发生的状态,还需要考虑达到该状态所可能采取的行动。另外一个区域负责对这个预测到的未来状态、行动对打分或者是做评估,在若干个评估结果中,选择出一个最优的结果,并且大脑认为该结果非常合理可行,这个时候,当该结果的评估价值远大于历史的平均水平时,多巴胺开始产生,并且急迫地驱动你去按照该行动去实现那个预期的未来。
伯努利的谬误:混淆似然与后验
在《伯努利的谬误》中,作者 Aubrey Clayton 指出了一个困扰了统计学三百年的根本错误,忽略基础概率或者叫做先验概率而直接使用基于频率的统计方法计算一件事情发生的可能性,是片面的,在很多行业当中,我们以为的基于频率的统计方法的客观性,其实会导致严重的错误。往往会造成的后果是:将似然概率(Likelihood)等同于后验概率(Posterior)。
而事实上,一件事情发生的可能性,本质上就是主观判断+客观数据共同决定的,只要提出可能性,这件事情就带进来主观色彩了,因为不同的人,给出的猜想集合本身就不一致,在数据到来之前,没办法确定谁的猜想集合是对的,谁的猜想是错的。
用数学语言来说,伯努利错误地认为:
$$P(F=f \mid S=s) \approx P(S \text{ is close to } f \mid F=f)$$
其中 $f$ 是事件的真实概率,$S$ 是采样得到的频率。左边是我们想要得到的——根据观测数据推断真实概率;右边是伯努利实际上证明的——在给定真实概率的条件下,采样频率会趋近于它。
看起来差不多,但差之毫厘,谬以千里。
伯努利的谬误用一句话概括就是:
采样的数据就足够拿来做推理。如果考虑做推理,伯努利利用似然概率来当作权重计算最终的后验概率。如果先验概率是均等的,那么,伯努利的计算方法的结果和贝叶斯是一致的,这是他的理论统治了半个世纪的关键——因为很多问题的研究,最开始是没有先验知识的,人们只能是均等分配先验概率。
这正是关键所在:当先验概率均等时,似然就是后验;但现实世界中,先验概率几乎从来不会均等。
从高斯到Fisher:频率学派的胜利与隐患
伯努利的谬误并非一个孤立的数学错误,它实际上奠定了整个频率学派统计学的基调。要理解这个谬误为何统治了三百年,需要回顾从高斯到Fisher的思想脉络。
高斯与最小二乘
19世纪初,高斯(Gauss)在研究天体测量误差时,提出了一套系统的方法:最小二乘法(Least Squares)。核心思想很朴素——给定一组观测数据,找到一组参数,使得模型预测值与观测值之间的误差平方和最小。
高斯的关键假设是:测量误差服从正态分布。 在这个假设下,最小二乘估计等价于最大似然估计(MLE)。换句话说,高斯的方法本质上就是找到使似然函数 $P(D \mid \theta)$ 最大的参数 $\theta$。
注意,这里只有似然,没有先验。高斯的方法在工程实践中极其有效——天文学家可以用它精确预测行星轨道,测量员可以用它校准大地坐标。它太好用、太成功了,以至于人们很少停下来追问:只看似然,够吗?
Galton与正态分布的信仰
弗朗西斯·高尔顿(Francis Galton)是正态分布的坚定维护者。他观察到,水果的大小受到诸多因素影响——朝向、叶子的遮挡面积、生长的坡度等——每一个因素单独对水果大小的影响符合正态分布。那么,所有因素联合作用的结果 $P(\text{Size} \mid F_1, F_2, \cdots, F_n)$ 也符合正态分布。
高尔顿最大的创新是发明了 quincunx(弹珠台)——一个直观的物理装置,让弹珠经过一系列钉子后落入不同的槽中,最终形成正态分布的形状。他还命名了"回归"(regression)这个概念。高尔顿不是严格的理论数学家,但他擅长通过实验和直观装置来解释统计规律。
正态分布如此优雅、如此普遍,以至于人们渐渐把它当作自然的法则,而非一种假设。当正态分布成为默认假设时,先验就变得"不重要"了——因为在正态分布下,似然估计和贝叶斯估计的结果往往是一致的。 1
这正是伯努利的谬误得以延续的温床。
Gosset与Student’s t
高斯的最二乘法有一个前提:需要足够多的数据来可靠估计方差。但在现实中,数据往往是稀缺的。
威廉·戈塞特(William Gosset)在吉尼斯啤酒厂工作时面临的就是这个问题——他只有很少的样本数据。他的革命性想法是:计算估计的标准差本身的变异度——即找到"误差的误差"。假设数据来自正态分布,戈塞特推导出了一个公式,能够在样本量有限的情况下,计算观测均值偏离真实均值的概率,同时考虑了均值的变异和变异本身的变异。这就是后来以笔名"Student"发表的 Student’s t 检验。
他的概率同时考虑了观测平均值的变异和观测变异本身的变异。
Gosset 的贡献在于,他让频率学派的方法在小样本场景下也能工作。但他同样没有触碰先验的问题。
Fisher:让频率学派成为"默认设置"的人
罗纳德·费舍尔(R.A. Fisher)是将频率学派方法论推广开来的关键人物。
Fisher 从小视力不好,但这反而让他擅长用图形来理解和建模问题。他最大的贡献是解决了一个实际问题:如何利用较少的样本数据做出推理。 他开发了一套针对数据处理的工具箱,生物学家不需要太多数学知识,只需选择合适的方法,就能从数据中得出结论。这对当时的生物学研究来说是革命性的。
Fisher 提出了 似然(Likelihood) 的概念。回顾伯努利的概率分布公式:假设瓮中黑石头的比例为 $f$,重复 $n$ 次独立实验,获得 $k$ 次黑石头的概率是:
$$ P\left(R=\frac{k}{n} \mid f, n\right) = \binom{n}{k} f^k (1-f)^{n-k} $$
Fisher 反过来思考:上面的概率公式前提是需要知道 $f$,但实际中我们往往不知道 $f$——我们只知道 $n$ 和 $k$。所以,可以把这个概率看作 $f$ 的函数,Fisher 称之为似然函数(Likelihood Function)。对它求导取极值,得到的 $f_{\max} = k/n$,这就是最大似然估计(MLE)。
到这里,作者在《伯努利的谬误》中指出一个关键的事实:
如果对所有 $f$ 取值的先验概率是相同的,那么,经由似然概率计算得到的 pathway probabilities 正比例于似然概率,从而得到的后验概率也正比于似然概率。
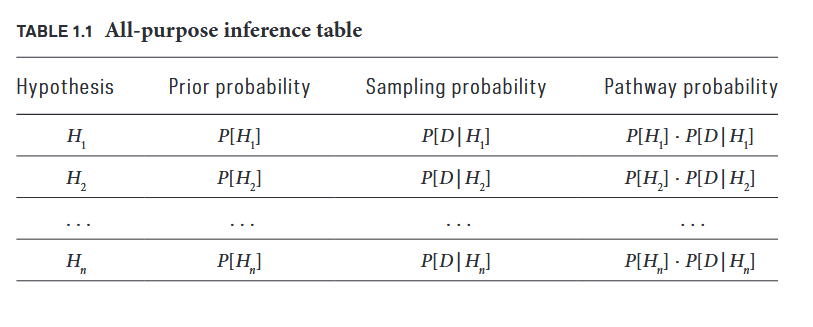 图1: 所有猜想都有一定可能通向证据,pathway probabilities衡量了该道路的宽阔程度,也最终决定了后延概率的大小。
图1: 所有猜想都有一定可能通向证据,pathway probabilities衡量了该道路的宽阔程度,也最终决定了后延概率的大小。
这正是 Fisher 方法能够成功,同时也是它隐藏风险的根源。 当先验均等时,最大似然就是最大后验,两者殊途同归。但 Fisher 的方法在本质上仍然是频率派的——它从不追问先验,也从不考虑替代假设。Pearson 后来发展出的 决策理论 衍生出了无偏估计(unbiased estimator)、统计功效(statistical power)、第一类错误(Type I error)、第二类错误(Type II error)和置信区间(confidence intervals)等概念,构成了现代统计学的基础框架。
这套框架太强大、太好用了,以至于整个20世纪的科学实践都默认采用频率学派的方法。伯努利的谬误就这样被包装成了"标准做法"。
7R等位基因:一个绝佳的例子
《贪婪的多巴胺》第7章提到了一个有趣的观点:拥有7R等位基因的人更倾向于迁徙到远方,因此7R是驱动人类远征的基因。书中给出的数据是:
- 短距离迁徙人群中,7R携带比例 $P(7R \mid D=\text{short}) = 0.32$
- 中等距离迁徙人群中,7R携带比例 $P(7R \mid D=\text{middle}) = 0.42$
- 长距离迁徙人群中,7R携带比例 $P(7R \mid D=\text{long}) = 0.69$
看起来证据很充分,对吧?长距离迁徙人群中7R携带比例最高,所以7R驱动了人类远征。
但这恰恰就是伯努利的谬误!作者展示的是 $P(7R \mid D)$——在某迁徙距离人群中7R的似然概率。而我们需要回答的问题是 $P(D \mid 7R)$——拥有7R基因的人当中,长中短距离迁徙的人占比是多少:回答了这个问题,才可以很好地回答7R是否是驱动人类远征的核心原因。
这里抽象一层:7R等位基因的发生是一个事件(事件A),人类迁徙距离的远近也是一个事件(事件B),如果我们想要研究事件A是否是事件B的原因,就需要计算$P(B|A)$:在贝叶斯公式中,具体体现在了$P(A|B)$是似然概率,$P(B)$是先验概率,$P(A)$是边缘概率,$P(B|A)$是后验概率。
如果我们假设先验概率相等:$P(D=\text{short}) = P(D=\text{middle}) = P(D=\text{long})$,那么结论确实成立。
但是,如果我们从常识出发:人类进行长距离迁徙一定是更困难的。假设:
$$P(D=\text{short}) = 0.6, \quad P(D=\text{middle}) = 0.3, \quad P(D=\text{long}) = 0.1$$
那么通过贝叶斯公式计算:
$$ \begin{aligned} P(D=\text{short} \mid 7R) &= 0.496 \\ P(D=\text{middle} \mid 7R) &= 0.326 \\ P(D=\text{long} \mid 7R) &= 0.178 \end{aligned} $$
结果出人意料:基于不同人群(按照迁徙远近划分三组:短,中,长)中携带7R基因的比例,再根据迁徙人群在所有人群中的比例(这里算是先验分布)拥有7R等位基因的人,在短,中,长距离迁徙人群中分别占一定比例。 这就是典型的幸存者偏差——我们只看到了那些成功远征的人身上的7R基因,却忽略了是否还有其他更大的人群以及他们中的7R等位基因携带情况。
注意:上面的先验并不是准确的,需要借助更多的证据或者调查研究来确定,但是具有说明性。
多巴胺 + 伯努利的谬误 = ?
将这两本书放在一起思考,我发现了一个有趣的关联。
多巴胺系统让我们关注"远体空间"——未来的可能性。但多巴胺在评估这些可能性时,并不考虑基础概率(先验)。它只看"如果我办成了这个事情,我就获得非常丰厚的奖励"(似然),而不看"我办成这件事情的可能性有多渺茫"(基础概率低)。
这不正是伯努利的谬误在大脑中的体现吗?
赌徒看着轮盘,多巴胺告诉他"赢的感觉太棒了"(高似然),却忽略了轮盘转到特定角度的基础概率极低(低基础概率)–只有先满足了轮盘转到特定角度的条件,获得大奖的似然概率才会高。
恋爱中的人被激情冲昏头脑,多巴胺说"这个人太完美了"(高似然:在恋爱中,往往是理想状态下的表现:$P(完美程度|理想状态)$很大),却忽略了长期关系中需要面对的现实:$P(完美程度|复杂琐碎的生活)$(是否在其他条件下,表现依然完美)。
创意工作者不断追求下一个作品,多巴胺说"下一个会更好"(高似然),却忽略了大部分创新尝试会失败的事实(低先验)。
大脑的多巴胺系统就像一个频率学派——它只关心数据本身的似然,而不考虑先验知识。
从决策论的角度看,这是一个 POMDP(部分可观测马尔可夫决策过程) 问题。大脑面临的状态不是直接可观测的——我们看到的是噪声测量(视觉、听觉等),需要通过贝叶斯推理来推断隐藏状态。理性决策需要两步:先用贝叶斯规则更新信念 $P(\text{state} \mid \text{evidence})$,再用期望效用选择最优行动。多巴胺系统跳过了第一步——它不去计算后验,直接用似然驱动行为。这在计算资源有限时或许是合理的近似(所谓resource-rational策略),但在先验分布严重不均匀时就会导致系统性偏差。
从医疗误诊到司法冤案
这种"忽略先验"的错误不只是理论问题,它在现实生活中造成了严重的后果。
在医疗领域,《伯努利的谬误》提到了一个经典案例:PET-CT设备的误报率只有7%,看起来很低。但如果你用贝叶斯公式考虑癌症的基础发病率,会发现检测报告为恶性肿瘤但实际是良性的概率高达87%。检查不是多多益善,需要首先根据病因发生的基础概率来判定是否需要。
更触目惊心的是司法领域的冤案。儿科医生 Roy Meadow 指控 Sally Clark 谋杀了自己的两个婴儿,理由是两个婴儿同时死于SIDS(婴儿猝死综合征)的概率是1/73,000,000。所以几乎可以确定是谋杀。
这个推理犯了两个错误:
- 忽略了先验:一位母亲连续杀害两个婴儿的基础概率同样极低;且只考虑了SIDS和母亲杀害两种假设,没有考虑其他的原因,例如环境因素,遗传因素等等。
- 假设独立:SIDS两次发生可能并非独立事件——家庭中可能存在共同的环境因素
荷兰护士 Lucia de Berk 的案件如出一辙。在她值班期间有多名患者死亡,检方认为这不可能纯属巧合。但正如统计学家 Mark Buchanan 在 Nature的文章 “Statistics: Conviction by numbers,” 中指出的:
法庭需要权衡两种解释:谋杀还是巧合。死亡不可能纯属偶然发生的论点本身并没有多大意义——例如,同一医院发生十起谋杀案的概率可能更低。重要的是两种解释的相对可能性。然而,法庭只得到了第一种情况的估计。
贝叶斯思维:对抗多巴胺的理性武器
那么,我们该如何应对?
贝叶斯给我们的启示是:在做任何推断之前,先问自己三个问题。
第一,我的假设是什么?它的先验概率有多大? 不要被眼前的数据蒙蔽,先想想这件事在一般情况下发生的概率。
第二,有没有其他可能的假设? 贝叶斯推理的核心是 pathway probability——每一条假设都是通往数据的一条道路,道路的宽度是先验和似然的乘积。我们不能只看一条路。
$$P(H_i \mid D) = \frac{P(D \mid H_i) P(H_i)}{\sum_j P(D \mid H_j) P(H_j)}$$
第三,我的数据量够吗? 太少,很难从中得到可靠的信息。但更根本的问题是——数据是从什么前提下产生的?
从神经科学的角度看,大脑的前额叶皮质负责"抑制控制"——它是与多巴胺冲动对抗的力量。《贪婪的多巴胺》将它描述为理性与欲望之间的博弈。而贝叶斯推理,或许就是前额叶皮质最好的武器:它迫使你在被多巴胺裹挟之前,先冷静地考虑先验概率和替代假设。
但这里有一个微妙的平衡。精确的贝叶斯推理在计算上是不可行的——假设空间通常是指数级的,后验分布的计算太过于浪费资源和时间。大脑必须使用近似策略:蒙特卡洛采样(从后验中抽取有限样本)、变分推断(用简单的近似分布代替真实后验),或者更粗糙的启发式。Resource-Rational Analysis告诉我们:在计算资源有限时,忽略先验而去直接用似然做快速判断,有时候反而是最优策略——只是当先验分布极端不均匀时,这个近似就会失效。多巴胺的"频率学派"策略,在大部分日常决策中是够用的,但在低概率高回报的场景(赌博、投机、一见钟情)中就会暴露出系统性偏差。
 图2: resource_rational_analysis的四个步骤
图2: resource_rational_analysis的四个步骤
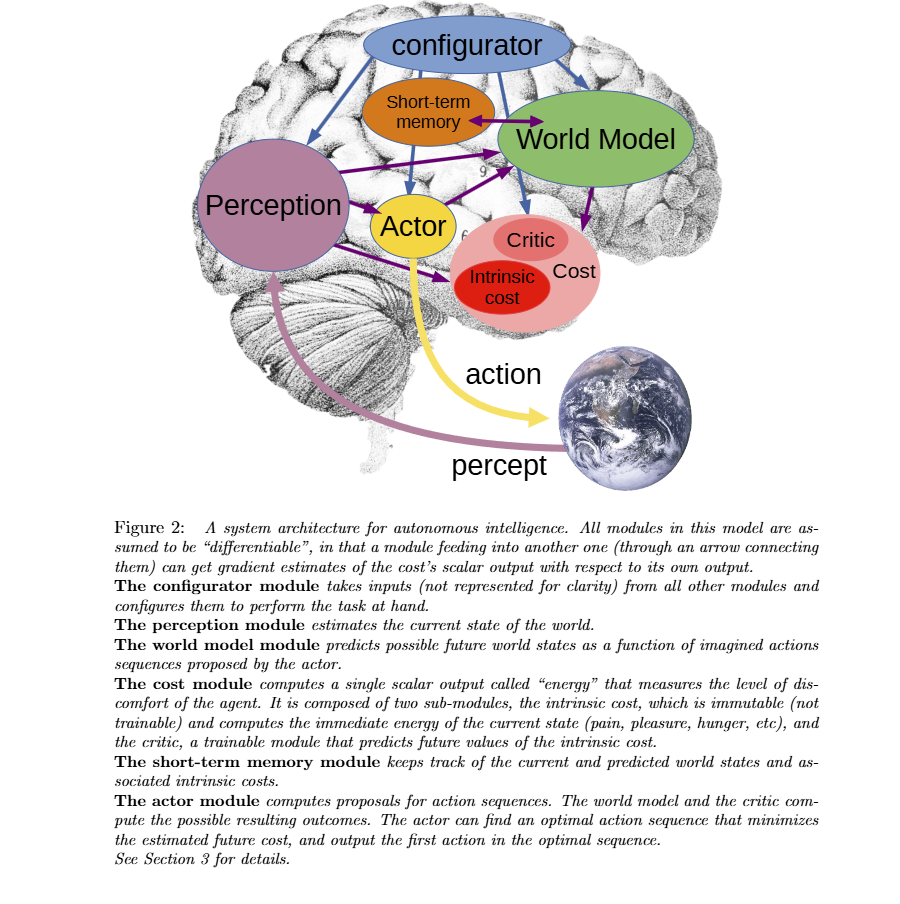
JEPA:大脑决策机制的工程化蓝图
杨立昆(Yann LeCun)提出的JEPA(Joint Embedding Predictive Architecture)为上述"打分+行动"的双系统提供了一个令人兴奋的工程化框架。
JEPA架构包含三个核心模块:
- Configurator:接收感知信息,确定生成什么参数给目标模块——类似于大脑的"近体/远体"空间划分机制,决定当前关注什么
- Cost模块:类似杏仁核,产生"痛苦"信号,Energy越大越痛苦——这就是打分系统,负责评估预测到的未来状态
- Actor模块:包含策略子模块,根据Perception输出action——这就是行动系统
- World Model模块:根据想象中的action和记忆,预测将来的世界状态(这里在什么纬度在什么空间做预测是Open的,如果在图像中,那么是不是会太精细,有些信息对下一步的动作选择没有帮助,预测太粗糙,又没有什么作用。)
- Short Term Memory 模块:存储当前的感知和预测结果,提供给World Model模块和Actor模块使用
JEPA作为大脑决策机制的工程化蓝图,给我们带来了重要启示:
- 模块化设计:大脑决策系统的模块化特性
- 预测编码:通过预测未来来理解现在
- 价值分离:区分预期价值和实际体验
- 无监督学习:大脑的自发学习机制
- 空间选择:在表征空间而非像素空间进行预测,这类似于大脑在抽象层次上进行推理
这个架构不仅推动了AI的发展,更为我们理解大脑决策机制提供了重要的理论框架和实验平台。
注意这个架构与多巴胺系统的对应关系:多巴胺专注于"远体空间"(未来可能性),而JEPA的Cost模块负责对这些可能性打分。多巴胺不是打分系统本身——它是打分结果与预期之间的误差信号。当Cost模块的评估远好于历史平均水平,多巴胺被触发,驱动Actor执行动作。
JEPA的发展时间线也值得注意:从2022年理论奠基,到2023年I-JEPA在图像自监督达到SOTA,2024-2025年扩展到视频理解(V-JEPA 2用100万小时视频训练),再到2026年Value-guided action planning——让JEPA具备了通过价值函数引导规划的能力。这一演进路径,几乎是在复现大脑从感知到决策的进化过程。
写在最后
多巴胺让我们向往远方的可能性,这是人类进步的驱动力。但如果不对这种冲动进行贝叶斯式的校正,我们就会不断陷入伯努利的谬误——把"看起来可能"当成"实际可能",把似然当成后验,把幸存者的故事当成普遍规律。
保持对可能性的热情,同时尊重基础概率。这或许就是两本书共同要告诉我们的。 最后的最后,永远相信,这个世界是灰色的,没有完美的人,完美的事情,完美的结果。
参考书目:
- 《贪婪的多巴胺》— Daniel Z. Lieberman, Michael E. Long
- 《伯努利的谬误》(Bernoulli’s Fallacy)— Aubrey Clayton
- 《Bayesian Models of Cognition》— Griffithifs, Chater, Tenenbaum et al.
- 《思考,快与慢》— Daniel Kahneman
- 《生活不是掷骰子》— 刘雪峰
延伸阅读:
- Yann LeCun, “A Path Towards Autonomous Machine Intelligence” (2022) — JEPA架构原始论文
- Ha & Schmidhuber, “World Models” (2018) — VAE+MDN-RNN+Controller架构
- Schulman et al., “Generalized Advantage Estimation” (GAE) — 优势函数的方差缩减方法
在贝叶斯理论中,$P(H \mid D) = \frac{P(D \mid H) P(H)}{P(D)}$,$D$是数据,$H$是假设,或者叫做先验。当似然函数$P(D|H)$是正态分布时,如果先验分布$P(H)$也是正态分布,那么后验分布仍然是正态分布。但是如果样本量很大(数据量很大),那么无论你选择什么合理的先验,后验分布都会几乎完全由似然函数决定。先验的影响会随着样本量增大而逐步被削弱。数学推导:假设数据$y_1,y_2,\cdots, y_n \sim \mathcal N(\mu, \sigma^2)$,先验分布$h \sim \mathcal N(\mu_0, \sigma_0^2)$,则后验分布$(h \mid y_1,y_2,\cdots, y_n) \sim \mathcal N(\mu_p, \sigma_p^2)$。其中:$$\mu_p=\frac{\frac{n\bar{y}}{\sigma^2}+\frac{\mu_0}{\sigma_0^2}}{\frac{n}{\sigma^2}+\frac{1}{\sigma_0^2}}$$其中,$\bar{y}=\frac{1}{n}\sum_{i=1}^n y_i$当 $n \to \infty$ 时,$\mu_p \to \bar{y}$,先验的影响被数据淹没——这就是为什么在大数据场景下,频率学派和贝叶斯学派的结论趋于一致,也是伯努利的谬误在数据充足时不易暴露的原因。 ↩︎