Learning就是通过迭代的方法找到更接近真实值的手段。
蒙特卡洛方法
当研究的问题动态模型未知的时候,怎么做策略估计?怎么做策略的改进?
在实际应用中,经常遇到模型未知的情况,无法像上一章节讲的,通过Bellman公式计算状态价值是根据模型(状态传递概率$p(s’,r|s,a)$)得到的,但是实际应用中经常遇到没有这样的概率可以依赖。
思路就是既然MDP利用环境状态传递概率(State Transition Probability)$p(s’,r|s,a)$来加权计算期望,在不知道这个概率的情况下,能否利用多次采集某状态出现的时候,环境给出的奖励Reward来平均计算,作为状态价值。
解法就是通过实验,多次执行episode,在每次的循环中,记录特定状态出现的次数以及循环结束之后所获得的奖励,最后依据大数定律,对积累起来的奖励求平均值,就当作该状态的价值。如果我们事先知道所有的可能状态(在该特定的policy下面,应该可以确定出来),那么就维护一个数组,存储每一种状态的上面的信息,最后所有状态的价值都计算出来就意味着策略评估完成了。 但是问题来了:如果一个episode持续很长时间,或者就无法结束,那么,蒙特卡洛方法这种依赖episode结束才可以获得状态价值的方法就无法应用,需要找到替代的方法来近似。 TD-learning就解决了这个问题。基于TD-Learning就衍生出一系列的方法解决这类问题。
MC Policy Evaluation and Control
$$G_t=R_{t+1} + \gamma R_{t+2}+ \gamma^2 R_{t+3} \cdots + \gamma^{T-1} R_{T}$$ $$v_\pi(s)=\mathbb{E}_\pi(G_t|S_t=s)$$
- 需要循环多次episode, 每次episode开始之后,每一次遇到感兴趣的$s$,记录$N(s)=N(s)+1$,并且把Return加进来:$G(\boldsymbol s,a)=G(\boldsymbol s,a)+r$
- 完成当前的episode后,计算$Q(\boldsymbol s,a)=G(\boldsymbol s,a)/N(\boldsymbol s,a)$ ->类似于累加Reward的过程
- 然后遍历$a$,更新策略:$\pi(s)=argmax_aQ(\boldsymbol s, a)$
Monte Carlo ES,是指每一个episode起始的状态选择是随机的,不能固定,避免有些状态永远无法被访问到。下图是书中的算法流程。
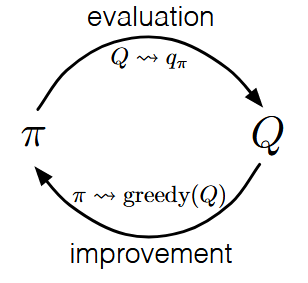
这部分也叫做MC Policy Improvement。 从给定的$\pi_0$开始,$E$代表策略估计(Policy Estimation),得到动作价值函数$Q_{\pi_0}$,采用贪心算法(greedy)找到使得$Q_\pi(\boldsymbol s, a)$最大的action: $\pi_1(\boldsymbol s) \leftarrow \arg max_{a}Q_{\pi_0}(\boldsymbol s, a)$
$$ \pi_0 \xrightarrow{\text{E}}Q_{\pi_0}\xrightarrow{\text{I}}\pi_1\xrightarrow{\text{I}}\pi_2\cdots \xrightarrow{\text{I}}\pi_*\xrightarrow{\text{E}}Q_{\pi_ *} $$
参看4.6 广义策略迭代(Generalized Policy Iteration)

On-Policy and Off-Policy
在学习Q值的过程中,我们会遇到两种情况:
- 和环境交互产生数据的策略就是我们正在优化的策略,这种情况叫做on-policy。
- 和环境交互产生数据的策略不是我们正在优化的策略,或者有一些是正在优化的策略产生的,有一些不是,这种情况叫做off-policy。
属于1的算法有:PPO,TRPO,A2C等;属于2的算法有:DQN,DDPG,TD3,SAC等。
TD Learning
MC方法需要走完一个完整episode才可以计算$Q_\pi(\boldsymbol s,a)$,但是TD方法不需要,每次采取完行动之后,立刻马上就可以更新状态价值。
该方法只是在特定的策略$\pi$下,不断迭代找到状态价值。所以,是一种Learning的方法。后面,Sarsa是加入了策略改进的,是GPI的一种。

Sarsa - State Action Reward State Action
Sarsa是on-policy TD control。
很自然地,通过上面的TD Learning,一边学习$Q$,一边采用$\epsilon \text{-greedy}$改进策略。具体过程如下:
 重点看$Q(S’,A’)$代表采取行动$A’$之后环境给出的状态为$S’$的行动价值,后面的Expected Sarsa改进为求所有可能造成$S’$的全部$a$的加权平均,希望能够更加快速贴近真实的行动价值。
重点看$Q(S’,A’)$代表采取行动$A’$之后环境给出的状态为$S’$的行动价值,后面的Expected Sarsa改进为求所有可能造成$S’$的全部$a$的加权平均,希望能够更加快速贴近真实的行动价值。
Q-Learning - off-policy TD control
Q-Learning是一种off-policy的学习+控制的方法,是因为:在每次迭代的过程中,Q函数会更加靠近Optimal Q value,且下一次采取的行动,会根据Q函数的输出,选择要么是最大化Q的动作,要么是为了探索,以较小概率采取其他非最大化Q的动作。
所以从这个角度理解,就会发现,Q-Learning每次更新的$Q$就是朝向Optimal Policy前进的,或者从控制的角度来看,被控对象看作是环境,如果被控对象从任何状态,采取某一种行动就可以获得最多的Reward,那么,这样的系统下,可能会收敛到同一个数值。但是,实际上,在不同状态下,如果采取相同的动作,会发现,有些动作会导致Reward很低,也就是不合理。所以,不同的状态,需要采取不同的行动,在每次行动中,得到对应的Reward,随着时间的推移,这些Reward积累起来的“求和”就逐渐“逼近了”状态价值的真实值。
Q-Learning把学习和策略优化分开,每次采取的行动不一定是根据上次学习到的最佳行动价值,就是在比较随机地选择行动的过程中,将“可能不是最好的行动”所带来的最好的价值$\max_a Q(S’,a)$加入到TD-Learning的行动价值更新中,以期望更快地调整行动价值,接近最优行动价值。这种做法的好处就是:做更多的探索动作,保证访问到更多的$(\boldsymbol s,a)$对,从而更接近真实的数值,而避免陷入局部的最优,出不来。

Expected Sarsa
行动价值的更新算法如下:
$$ \begin{aligned} & Q(S_t,A_t) \leftarrow Q(S_t,A_t)+\alpha[R_{t+1}+\gamma \mathbb{E}[Q(S_{t+1},A_{t+1})|S_{t+1}] - Q(S_t,A_t)] \\ & \leftarrow Q(S_t,A_t)+\alpha[R_{t+1}+\gamma \sum_a[\pi(a|S_{t+1})Q(S_{t+1},a)] - Q(S_t,A_t)] \end{aligned} $$
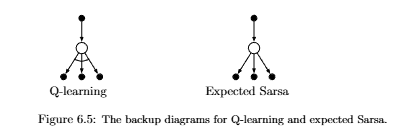 Expected Sarsa在更新的时候,考虑了所有的action,而不是单个的action的行动价值。在这里,不得不提,4. baseline的引入,这一部分$\sum_a[\pi(a|S_{t+1})Q(S_{t+1},a)]$就是对当前策略在当前状态下的平均水平评估,作为一个基线(baseline),如果某个action的行动价值高于这个基线,那么就说明这个action是一个好action,反之则是一个坏action。根据这个基线作为目标,比根据单个Q作为目标更具有客观性,只不过Q函数的更近进度可能会变慢,达到同样接近Optimal Q Value所需时间变长。
明显的缺点是需要计算期望,在性能方面差。
Expected Sarsa在更新的时候,考虑了所有的action,而不是单个的action的行动价值。在这里,不得不提,4. baseline的引入,这一部分$\sum_a[\pi(a|S_{t+1})Q(S_{t+1},a)]$就是对当前策略在当前状态下的平均水平评估,作为一个基线(baseline),如果某个action的行动价值高于这个基线,那么就说明这个action是一个好action,反之则是一个坏action。根据这个基线作为目标,比根据单个Q作为目标更具有客观性,只不过Q函数的更近进度可能会变慢,达到同样接近Optimal Q Value所需时间变长。
明显的缺点是需要计算期望,在性能方面差。
Consider the learning algorithm that is just like Q-learning except that instead of the maximum over next state–action pairs it uses the expected value, taking into account how likely each action is under the current policy. Given the next state $S_{t+1}$, this algorithm moves deterministically in the same direction as Sarsa moves in expectation, and accordingly it is called Expected Sarsa.
Deep Q-Network
在实际应用中,遇到的问题经常是:$(S,A)$的取值非常广泛,每次迭代很难做到遍历每一个动作价值。 所以,能不能有一种方法,可以找到一个函数,输入为$(S,A)$(后面会更新成),输出就是价值。很多研究都是提出一个Linear Function Approximator去解决$Q$的估计问题,该论文提出利用ANN,非线性神经网络近似函数:neural network function approximator。 论文中提到:当尝试使用非线性的函数去逼近$Q$的时候,经常会遇到函数不稳定或者是发散的问题,具体的原因如下:
- agent观察到的序列前后是有关联的,所以在某一段时间内的迭代过程,数据的相似性较大,会“引导”策略向不正确的(和整个数据代表的分布)方向前进,最后验证的时候,会发现在某些场景下agent的输出很优秀,但是其他的场景下表现较差。
- 对Q做微小的调整,可能会造成$\pi$剧烈的变动,从而造成之后采集到的数据分布发生剧烈变动,也造成了待估计的$Q$和引入的目标行动价值函数(target action-value function)之间发生剧烈变动。
解决的思路是:
- 利用生物体的回忆过往experience replay,将数据的前后关联打散,并且在输入到学习网络之前,对数据进行平滑处理。
- 对$Q$的估计,整体还是使用迭代的方法,不过$\gamma \max_{a’}Q(\boldsymbol s’,a’;\theta^-)$这一项中的$\theta^{-}$不会每次迭代都更新,而是受到一个参数$C$(多少次迭代)控制何时去更新。在论文中,作者称$Q(\boldsymbol s’,a’;\theta^-)$这一项为target action-value function。 $$ \boldsymbol e_t=(\boldsymbol s_t,a_t,r_t,\boldsymbol s_{t+1}) $$ 如果将上面的这些输入存储起来,构建一个库$D_t={\boldsymbol e_1,\cdots \boldsymbol e_t}$(agent’s memory)。 每次迭代$i$,以下面的函数作为损失函数,通过stochastic gradient decsent方法,可以找到$\nabla\mathcal{L}_ i(\theta_i)$,从而更新$\boldsymbol \theta$,作为下一次计算$Q$的参数。
$$ \begin{aligned} & \mathcal{L}_ i(\theta_i)=\mathbb{E}_ {(\boldsymbol s, \boldsymbol a, r, \boldsymbol s’)\sim U(D)}[r+\gamma \max_ {\boldsymbol a’}Q(\boldsymbol s’,\boldsymbol a’;\theta_i^-)-Q(\boldsymbol s,\boldsymbol a;\theta_i)] \leftarrow \mathbb{E}\text{(reward + max target - current)} & \end{aligned} $$
- 下面的算法中,$\hat Q$就是target action-value function,它的大小由$\theta^-$和$\boldsymbol e_i$决定。
- $\theta$的更新方向是$\nabla\mathcal{L}_i(\theta_i)$
- 经过$C$次迭代,更新$\hat Q$
