动态规划
在环境动力学模型$p(s’, r|s, a)$已知的情况下,学习状态价值或者是动作价值。
策略评估–Policy Evaluation
讨论的是如何在已知策略的情况下计算状态价值函数,从而得到采用该策略的价值有多大。
在DP当中policy evaluation就是计算状态价值函数,也就做prediction problem。

这里讨论的是如何计算状态价值函数,该函数是从初始的状态(不准)迭代计算的,迭代的终止条件是状态价值的更新幅度小于一个预设的阈值$\theta$,也就是说当状态价值函数的更新幅度小于$\theta$的时候,就认为状态价值函数已经收敛了。
还有一个具体的细节:提到了两种状态价值迭代的方式,一种是维护上一次所有状态价值的数组和当前状态价值的数组,计算当前的状态价值的时候只参考上一个状态的数组,还有一种是直接将上一次的数组某个状态价值更新了,其他状态价值的计算直接用更新了的。后面的讨论默认都是基于第二种方式。
明显地,想要实现上面的计算过程有一个概率需要知道,那就是状态转移概率$p(s’, r|s, a)$,也就是在状态$s$下采取行动$a$之后,转移到状态$s’$并且得到奖励$r$的概率,这也是叫做环境模型已知。这个概率在DP当中是已知的,在后续的MC和TD当中是未知的。
策略改进–Policy Improvement
讨论的是在已有一个策略,且该策略所对应的状态价值已经确定的情况下,如何调整$a=\pi(s)$为$a’=\pi’(s)$,使得改进了的策略在将来与环境交互中获得更多的奖励。
想法的来源是在状态为s的情况下,我们知道,继续沿用策略$\pi$, 所得到的后续收益就是$V(s)=\mathbb{E}(G|S=s)$。那么,一个问题来了:有没有可能,在状态为$s$的情况下,采取一个不同于$\pi(s)$的行动$a’$, 从而得到一个更大的收益$\mathbb{E}(G|S=s, A=a’)$,也就是说,是否存在一个行动$a’$使得$Q(s, a’) > V(s)$。如果存在这样的行动,那么我们就可以把当前状态下的策略改进为$\pi’(s)=a’$, 也就是说,在状态为$s$的时候,不再按照之前的策略$\pi(s)$来选择行动,而是按照新的策略$\pi’(s)=a’$来选择行动:因为采取$a’$获得了更多的收益。这种单个状态下的动作改变,其实是更普遍的情况下的一个特例,普遍地,在已知策略$\pi$和状态价值$V _{\pi}(s)$的情况下,我们可以通过计算$Q _{\pi}(s,a)=\mathbb {E}(r _{t+1}+ \gamma V _{\pi}(s’)|S=s,A=a)=\sum _{r _{t+1},s’}p(s’,r _{t+1}|s,a)\big ( r _{t+1}+ \gamma V _{\pi}(s’)\big )$来找到一个行动$a’$使得$Q _{\pi}(s,a’) > V _{\pi}(s)$,从而把当前状态下的策略改进为$\pi’(s)=a’$。
贪心策略:对于任意一个状态$s$,遍历所有可能采取的行动,看看哪种行动的状态-行动价值最高,那么,当后面遇到状态为$s$的时候,就直接采取行动$\pi’(s)$。 $$ \pi’(s) = \arg \max _a Q _{\pi}(s,a) = \arg \max _a \sum _{r _{t+1},s’}p(s’,r|s,a)\big ( r _{t+1}+ \gamma V _{\pi}(s’)\big ) $$
之所以叫做贪心策略,是因为策略的选择还是基于没有变化的价值函数$V(s)$,但是,真实的情况是,当策略发生了变化,对于环境的影响也会发生变化,具体体现在$p(s’,r|s,\pi(s))\neq p(s’,r|s, \pi’(s))$产生变化,之前基于旧策略$\pi$的评估已经过时。
书中4.2节是一个很重要的转折,将我们从确定策略得到的有用结论,推广到更具一般性的stochastic策略的情况,后续的章节都是基于这个转折点来展开的。强烈推荐好好研读这部分内容。
策略迭代–Policy Iteration
4.2 策略改进中,使用的是基于旧策略$\pi$的评估函数$V_{\pi}(s)$对对策略进行改进;能否将更新了策略放入环境中,使得可以计算出该更新策略的最新评估函数$V_{\pi’}(s)$,然后基于新的评估函数继续提升策略。

- 给定策略$\pi$和初始化的状态价值函数$V(s)$,对于每一个状态$s$,按照上面的迭代计算方法来更新状态价值函数,直到状态价值函数收敛。
- 利用价值函数提升策略,得到新的策略$\pi’$。
- 做判断:如果所有的$s$, $\pi(s)=\pi’(s)$,说明策略稳定,找到最优贪心策略$\pi_*$,算法结束;如果存在某个状态$s$使得$\pi(s)\neq \pi’(s)$,说明策略不稳定,继续回到步骤2进行下一轮的迭代。这里,对于确定性的策略来说,很容易比对$\pi$和$\pi’$。但是,对于不确定性的策略,需要比对$\pi(s)$和$\pi’(s)$的概率分布函数是否一致。
上图的两个关键是:在Policy Evaluation阶段,$V(s)$利用当前策略更新,在Policy Improvement阶段,利用更新的 $V(s)$ 去寻找使得当前行动价值最大的行动。
价值迭代–Value Iteration
JCR的例子的实现过程,是将策略评估和策略改进分开进行的,具体地讲,就是在策略评估阶段,需要针对每个状态,在给定的策略下,做Bellman计算得到新状态价值,然后拿着这个$V_{k+1}(s)$给到策略改进阶段,在这个阶段当中,针对每个状态,遍历所有的可能行动,计算得到一组行动价值$Q_{\pi}(s,a)$,然后选择最大的行动价值,替换掉当前状态对应的行动。完成上述的一个循环过程,是很耗时间的。
价值迭代解决的是如何提高上述两个阶段的效率,以达到一个更快找到最优策略的目的。
思路就是在策略评估阶段,先不要着急根据当前的策略去更新状态价值,而是遍历一下所有的行动,找到在当前状态下使得行动价值最大化的那个行动,直接替换该状态的行动,根据这个行动做Bellman的计算更新状态价值,最终循环这个过程直到状态价值变化很小达到收敛。

异步动态规划–Asynchronous Dynamic Programming
这部分着重讲到了当面对现实问题的时候,状态的数量很庞大,可能采取的动作也很庞大,在这样的情况下,就算使用状态迭代的方法,也会造成很重的计算负担,实时性很差。异步动态规划可以解决这个问题。在计算的时候,可以选择性地保留一些状态,对这些状态进行迭代。 这部分并没有说具体的相关算法,但是提到了agent可以根据自己的经验,有选择地对某些状态进行迭代更新。后续应该会有相关的算法。
广义策略迭代–Generalized Policy Iteration
是一个泛指,指代策略评估(Policy Evaluation)和策略改进(Policy Improvement)的交互过程。可以是顺序进行,也可以是融合在一起进行。
对立性:策略评估是认知的过程,即对当前的策略进行“客观”的分析,通过状态价值函数体现出来;策略改进,是打破策略评估的结果,在现有的策略框架下采取其以外的行动重新构建一个新的策略框架,这个时候,策略评估就需要针对新的策略进行重新分析。 所以说,对立体现在策略评估想要维护当前的现状,而策略改进想要打破现状,追求更高的状态价值。
合作性:没有策略评估,策略改进是没有依据的,因为策略评估给出了当前的状态价值,相当于给出了参考。没有策略改进,策略评估和现实世界距离太远,评估结果根本体现不出来现实世界的意义。
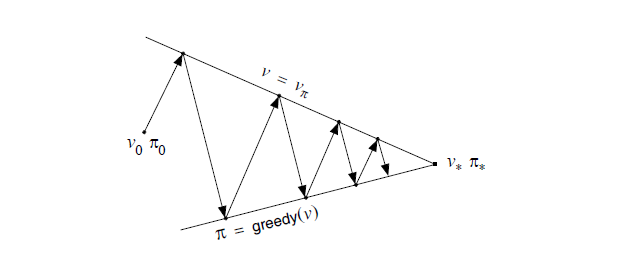
正如作者解释下面这张图,上面的策略评估这条线,代表为了找到真实的状态价值函数而做出的努力,下面的策略改进这条线,为了找到使得状态价值函数最大化的策略而做出的努力,两条线在不同的方向上面发展,最后发现各自做出的努力所取得的进展很小($\Delta < \epsilon$)的时候,就当作两条线相交,此时策略最优,状态价值函数最客观。
到这里,我突然想起来有人提过,强化学习就像一个自动控制系统当中的PID控制器,先通过反馈得到期望和状态的差,然后采取行动改变执行器的输出,接着反馈发生变化,再计算新的期望和状态的差(通常情况下,这个差会变小,假设期望值不变)。
实际案例:Jack’s Car Rental Problem
研究如何运营A和B两地的车辆,首先需要实验当A和B之间不转运车辆的情况下,A和B保留车数量和收益的关系。
这个例子非常好地帮我我们理解了遇到一个问题,如何抽象状态,抽象行动,构建策略和寻找到最优的策略。
行动
为了应用动态规划的方法,需要设定行动和状态,这里的行动是转运车辆的数量,描述为如下的形式: 假设从A到B转运车辆的数量设定为 $x$, 当$x > 0$表示运送$x$辆车从A到B,当$x < 0$表示运送$-x$辆车从B到A。
状态价值
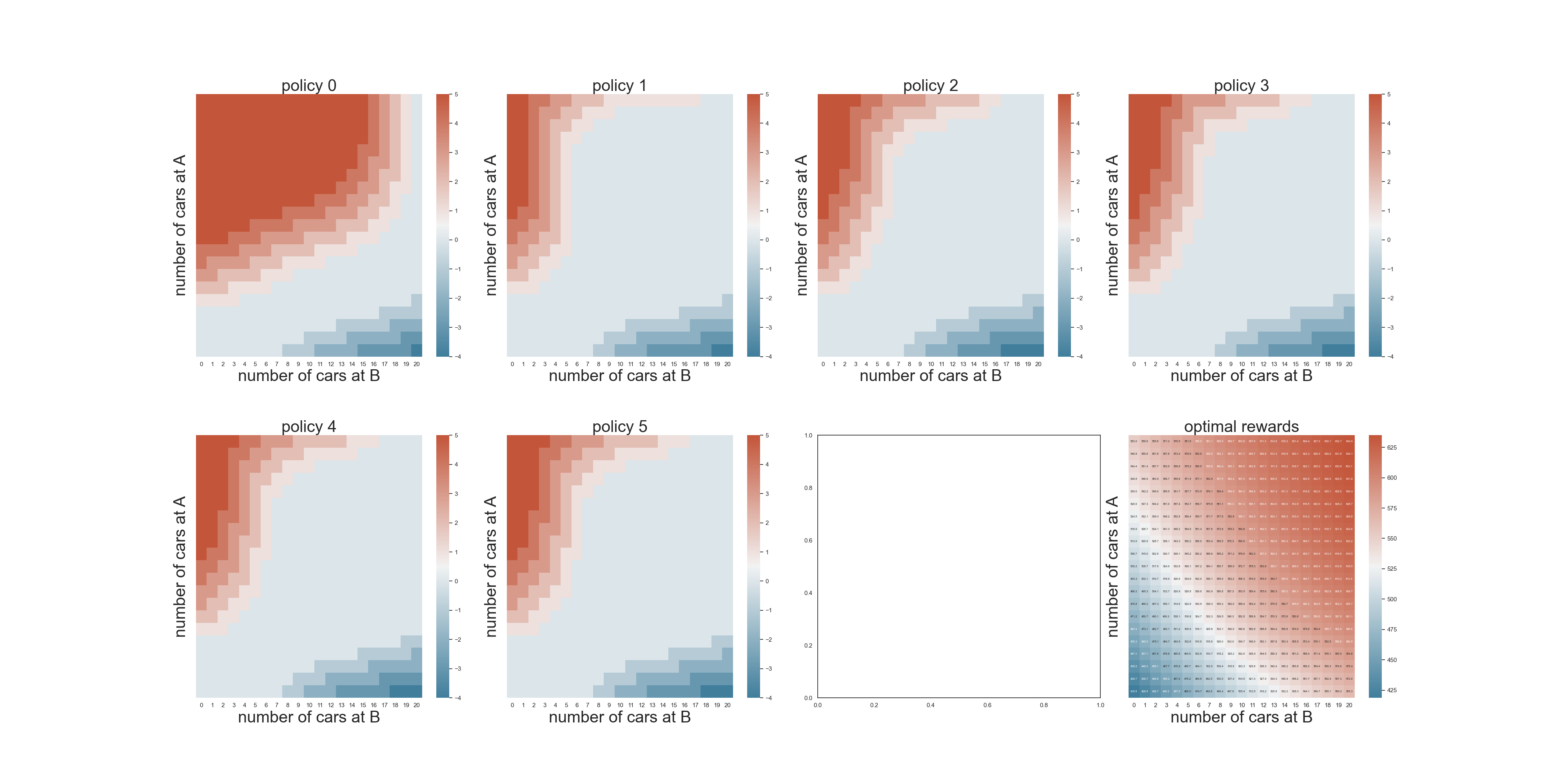
可以想象成一个二维的地图,y轴上面是A地的车辆数量分布,x轴上面是B地的车辆数量分布,z轴是$(x, y)$的高度,就是该状态下的收益或者价值(value) 参见下面的热力图的最后一张子图。
updateStateValues函数利用给定的行动遍历当前状态进行了Bellman方程的应用计算得到新的状态价值。
策略
策略可以想象成一个二维地图,x轴上面是A地的车辆数量分布,y轴上面是B地的车辆数量分布,z轴代表行动当中的某一个取值。
策略评估和策略改进
初始的策略可以选择是到了晚上不移动任何车辆,然后在状态上遍历所有可能的行动来更新状态收益,从状态收益当中选择一个最大的,从而对应的那个行动就变为该状态下的行动,从而完成对当前状态的策略改进,这里采用了贪心的改进策略,后续应该会遇到更加合理的改进方法。
numberofMoving这个二维数组存储了最新的策略。
Poisson分布: 在一个采样间隔里面,一个随机事件发生的次数有一个期望值 $\lambda$,那么,当事件在该采样周期内发生了 $n$ 次的概率为:
$$ P(\lambda, n) = \frac{\lambda^n}{n!}e^{-\lambda} $$
代码实现过程中遇到的理解问题
- 策略理解不够深入,没有创建策略的二维数组来存储策略。
- 策略的评估没有做从初始的策略和状态直接进行策略改进,查看输出结果不对。– 应该先做好策略评估,也就是遍历所有状态,按照初始的策略进行迭代,得到在该策略下的状态价值函数,在这里就是二维的数组
stateValues,然后拿着这个更新了的数组来找到最优的行动。 - 跟
gridworld相比,这次的不确定的是策略,具体来说就是当处在某一个状态,例如A处存留10辆车,B处存留7辆车,到了晚上应该从A到B运输多少量车,是需要尝试的,通过不同的尝试之后,就得到第二天不同的A和B的留存车辆状态,通过策略评估得到状态价值函数,从状态价值函数找到最优的行动。 - 在更新状态价值的函数当中
updateStateValues, 这个函数关心的问题是从给定状态$s$转移到新状态$s’$(有很多种可能性,例如A点出租了2台车,有3台车归还拥有一个概率$P$, A点出租了5台车有6台车归还拥有不同的概率$P’$,但是都造成到了晚上A点拥有相同的剩余车数量,像这种情况需要对泊松分布的高概率事件数量进行遍历,把造成晚上都是某个数量车的所有情况的概率加权考虑进去。这个泊松分布的高概率事件数量如何定义?从二维分布图上,可以指定一个高于0的水平直线,高度是$\epsilon=0.01$,代表了接车或者还车数量为n的事件发生概率低于0.01的n统统排除在外,只考虑比其发生概率更高的n),这个转移是通过行动$a$来实现的,所以在这个函数当中,需要传入行动$a$,然后根据行动$a$来计算状态价值的更新。 - 还是在
updateStateValues函数当中,当天的借车还车数量是很多种可能性的,$P(s’, r|s, a)$,仔细看这个条件概率里面的$a$是确定的,也就是前一天晚上的挪车成本在第二天早上就确定了,不确定的部分是第二天一整天下来的借车数量–利用概率对这部分的收益求平均值。所以updateStateValues函数当中的reward不应该按照下面的计算方法加入到概率的加权求和。reward = (rentalNumA + rentalNumB) * CONST_SINGLE_REWARD - abs(action) * CONST_MOVING_COST
而是应该
reward = (rentalNumA + rentalNumB) * CONST_SINGLE_REWARD
最后再把前一天晚上的成本加入到里面去。
再来把Bellman equation列在这里, 公式中$a$是确定的,所以采取行动的成本就确定了,但是第二天的白天状态切换的过程是随机的,满足泊松分布,这部分的收益是需要求期望的。
$$ v_{\pi}(s) = \sum_{a} \pi(a|s) \sum_{s’,r} P(s’, r|s, a) [r + \gamma v_{\pi}(s’)] $$
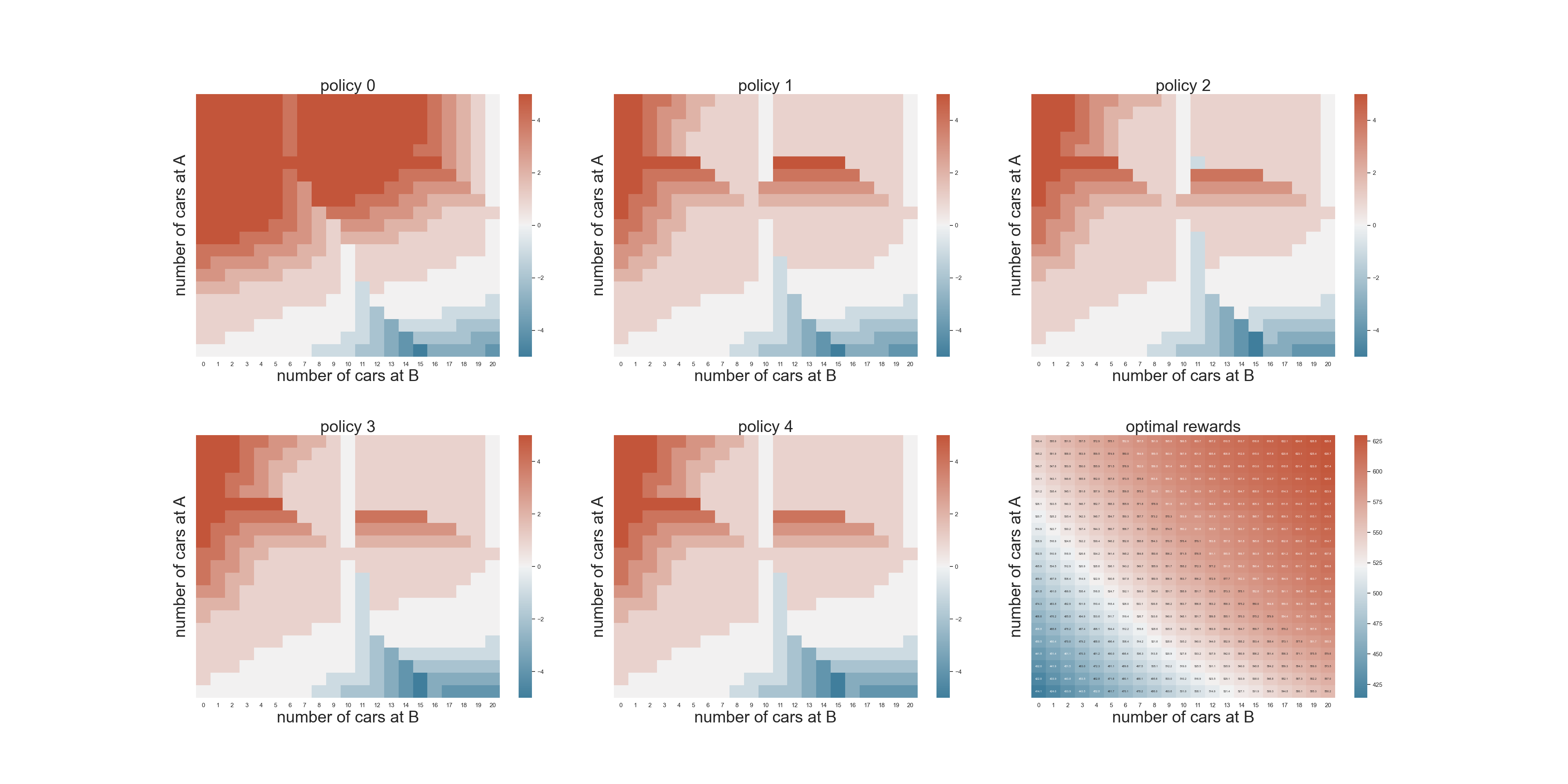
Exercise 4.5,Jack的员工可以下班帮忙开车和停车场空间限制场景加进来。
需要改动的地方在于价值函数,也就是updateStateValues当中。
最终的计算结果如下:
实际案例: 赌徒(Gambler)问题
具体的问题描述就不在这里赘述了。下面记录一下实现代码过程中遇到的问题。
代码实现过程中遇到的理解问题
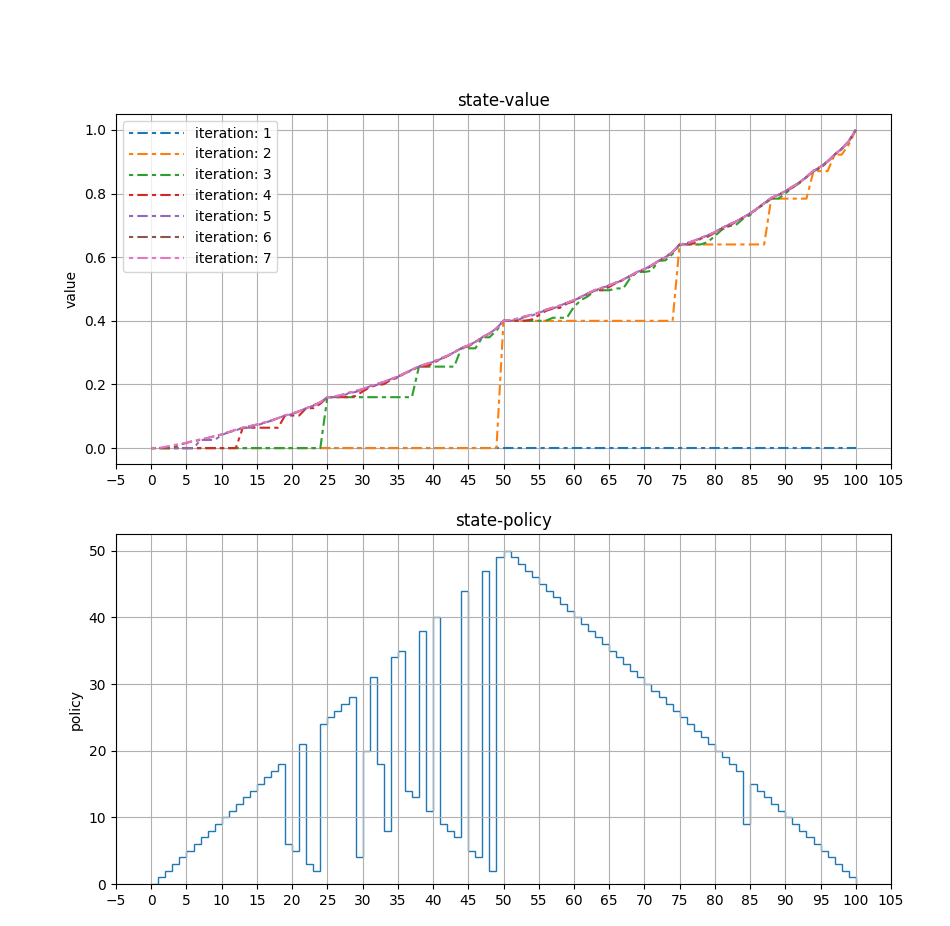
- 价值迭代最核心的点是在某一个状态$s$下,直接遍历所有的actions, 计算出一组$Q(s,a)$, 在这组数当中找到最大的那个,对应的$a$变为$\pi(s)$,并且需要随时将更大的$Q(s,a)$替换掉当前的状态价值函数$V(s)$。这里需要注意,可能在尚未找到最优动作之前,$V(s)$已经做了若干次的更新。
updateStateValue函数需要根据Bellman方程来更新状态价值,我最开始的实现错误地将Reward设置为1,这样造成的结果是计算出很大的$v(s)$。- 最后计算出来的策略结果和书中有出入,作者提到了最优解是不唯一的,我仔细看了最后一次迭代的中间结果,发现采取两个不同的行动,对应计算出来的状态价值差距特别小,在小数点后10位了,所以这种情况下,其实选择任意一个都是最优的。
上面的代码运行结束,可视化得到价值迭代过程和最优策略:
外部参考
最终的结果展示采用热力图的形式,使用了seaborn库,参考了这个链接:
https://seaborn.pydata.org/examples/many_pairwise_correlations.html
学习时间线索
2024年10月
- 读Sutton’s Book 第四章节
- 做了一些笔记,试图理解其中的概念。
2025年1月
- 自己实现Jack’s Car Rental 问题
- 暴露出来了[代码实现过程中遇到的理解问题](### 代码实现过程中遇到的理解问题)
2025年2月
- 春节回来完善JCR
- 核对结果和画图展示