基础概念
智能体和环境交互
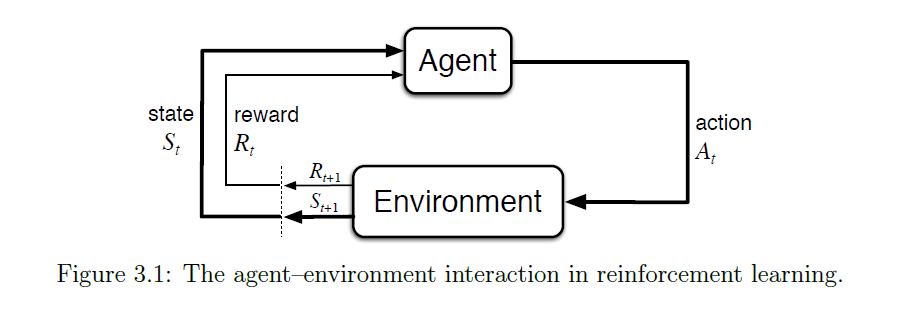 图1: Agent 与环境交互的基本结构。Agent 根据当前状态 $s_t$ 选择动作 $a_t$,环境依据状态转移概率 $p(s’,r|s,a)$ 返回下一状态 $s_{t+1}$ 和奖励 $r_t$。
图1: Agent 与环境交互的基本结构。Agent 根据当前状态 $s_t$ 选择动作 $a_t$,环境依据状态转移概率 $p(s’,r|s,a)$ 返回下一状态 $s_{t+1}$ 和奖励 $r_t$。
上面的图展示了RL智能体与环境交互的结构。这个示意图是很广义和普遍的:action可以是加载在机械臂电机上的控制电压或者是PWM信号,也可以是高级别的决策,例如是否要变道;state也比较灵活,可以看作是传感器回传的数据,也可以看作是在空间中特定符号描述的物体信息。
奖励
奖励这个概念我认为比较模糊,或者说它的来源可以是人为设计,也可以是环境给出。在机器人领域,奖励稀疏是一个常见问题,没有奖励的情况下,智能体很难学到真实的状态价值或者动作价值,那么策略的优化就很难进行下去。针对这个问题,后续专门讨论。
策略
策略$\pi$是智能体在状态$s$下对动作$a$的选择,或者是一个从状态到动作的映射关系。它可以是一个确定性的函数,例如DDPG和TD3那样输出准确的动作,也可以是一个随机的概率分布,例如PPO输出的是动作的高斯分布期望,可以利用这个期望生成一个分布,然后从分布中采样出来一个具体的动作。
状态价值$V(s)$
系统在状态$s$下,根据某个策略$\pi$采取行动,在后续和环境交互的过程中,得到的收益$G$的期望。
$$ \begin{aligned} & V(s)=\mathbb{E} _{\pi}(G|S=s) \\ & G=R _{t+1} + \gamma R _{t+2}+ \gamma ^2 R _{t+3} \cdots =\sum _{k=0}^{\infty}\gamma ^k R _{t+k+1} \end{aligned} $$
行动价值$Q(s,a)$
在状态$s$下,采取行动$a$之后,在后续和环境交互的过程中,得到的收益$G$的期望。 $$ \begin{aligned} & Q(s,a)=\mathbb{E} _{\pi}(G|S=s,A=a) \\ & G=R _{t+1} + \gamma R _{t+2}+ \gamma ^2 R _{t+3} \cdots =\sum _{k=0}^{\infty}\gamma ^k R _{t+k+1} \end{aligned} $$
Bellman方程:状态价值和行动价值的递归计算方法
如图5是用将来的状态价值估计当前状态价值的图形化解释。
前后状态价值的递归关系: $$ V(s_t)=\sum _{a\in \mathcal A}\pi(a|s_t)\sum _{s’,r}p(s’,r|s,a)\big(r+ \gamma V(s’)\big) $$
注意,这里的计算跟策略有关。
行动价值的递归关系:
$$ Q(s_t,a_t)=\sum_{s’,r}p(s’,r|s_t,a_t)\big(r+\gamma V(s’)\big) $$
虽然这里并没有显式体现策略的概率,但是$s’$的分布是受到策略的影响的,其实体现在了环境动力学$p(s’,r|s_t,a_t)$。
2025-5-27 value function的进一步清晰:
在看Policy Gradient的时候,推导$\nabla_\theta J(\theta)$遇到了理解value function不透彻的问题,其实是卡在没有搞清楚Reward和Return的区别:
Reward:状态切换的时候,环境除了告诉智能体下一个状态是什么,还告诉了奖励是多少。
Return: 是一个长期的量,通过时间的积累,多次Reward计算得到的。随着状态的不断向前迭代,将所有的奖励带上discount相加(因为将来的奖励具有很大的不确定性,不可以原样加进来)得到$G(s)$,对$G(s)$求期望才是Return。
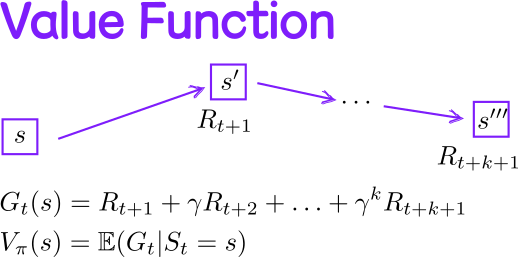 图2: 状态价值函数 $V(s)$ 的直观理解。价值是沿轨迹对折扣奖励的累计期望。
图2: 状态价值函数 $V(s)$ 的直观理解。价值是沿轨迹对折扣奖励的累计期望。
 图3: 动作价值函数 $Q(s,a)$ 的直观理解。在状态 $s$ 下采取动作 $a$ 后的折扣累计奖励的期望。
图3: 动作价值函数 $Q(s,a)$ 的直观理解。在状态 $s$ 下采取动作 $a$ 后的折扣累计奖励的期望。
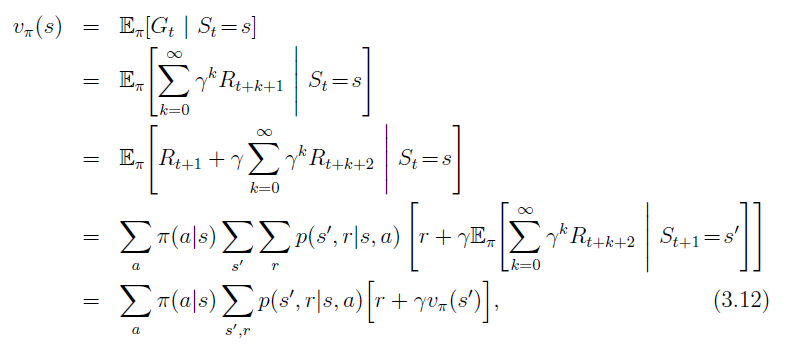 图4: Bellman方程:状态价值函数的图形化解释。价值从终端状态沿时间反向累积。
图4: Bellman方程:状态价值函数的图形化解释。价值从终端状态沿时间反向累积。
上面的公式的图形化解释,就是下面的图。Backup Diagrams体现出来$V(s)$可以通过后续action和reward倒推出来。那些分叉的树杈就像是求和当中的某一个单项,它们作为基来对最终的value叠加求和,每一条边是状态转移的概率,概率当作权重。
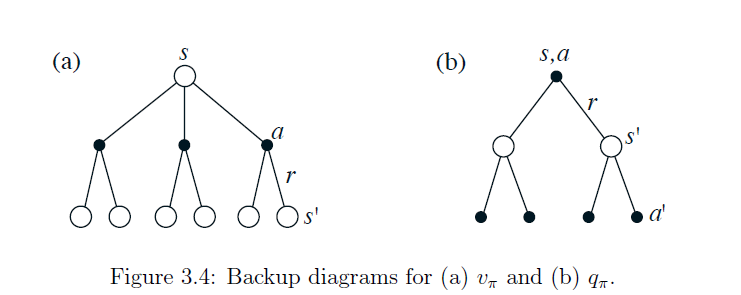 图5: Bellman 备份图示意。每个状态的 value 通过后续动作和奖励的加权求和来计算。
图5: Bellman 备份图示意。每个状态的 value 通过后续动作和奖励的加权求和来计算。
最优策略和最优价值函数
强化学习经常需要解决的问题是如何寻找到最优的policy:$\pi_{\star}$,使得对于任何一个$s$,都有$v_{\pi _{\star}}(s) \geq v _\pi(s)$。 记为:
$$v_\star(s)=\underset{\pi}\max v_{\pi}(s)$$
对应的动作价值函数: $$ Q_\star(s,a)=\underset{\pi}\max Q_{\pi}(s,a) $$
还有一个性质,就是最优策略的价值函数,等于最优策略的动作价值函数中,使得$Q_\star(s,a)$最大的动作对应的动作价值:
$$ \begin{aligned} & v _\star(s)=\max _a Q _\star(s,a) \\ & =\max _a \sum _{s’,r} p(s’,r|s,a) \big( r+\gamma v _\star(s’) \big) \\ \end{aligned} $$
最优策略的动作价值函数: $$ \begin{aligned} & Q _\star(s,a)=\sum _{s’,r} p(s’,r|s,a) \big( r+\gamma \max _{a’} Q _\star(s’,a’) \big) \\ \end{aligned} $$
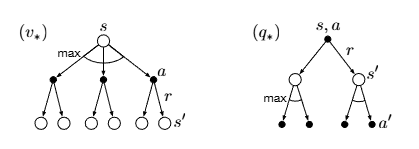 图6: 最优 $V_\star$ 与 $Q_\star$ 的备份图。最优状态价值反向计算与动作价值的反向计算。
图6: 最优 $V_\star$ 与 $Q_\star$ 的备份图。最优状态价值反向计算与动作价值的反向计算。
状态价值和动作价值之间的转换关系
- 给定所有的$Q_{\pi}(\boldsymbol s, a)$和$\pi(a|\boldsymbol s)$,如何推导$v_{\pi}(\boldsymbol s)$
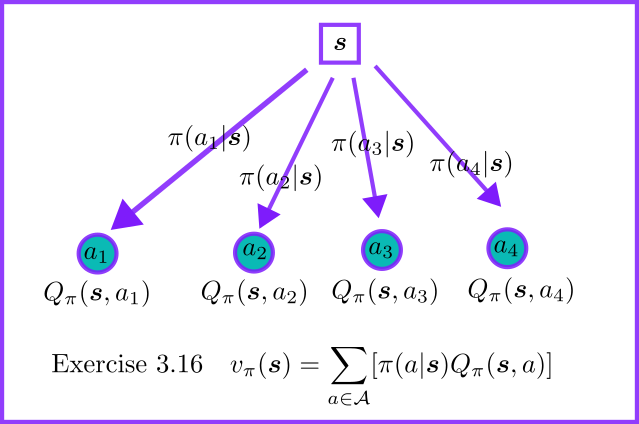 图7: 状态价值与动作价值的关系。给定 $Q_\pi(s,a)$ 和 $\pi(a|s)$,通过对所有动作加权求和得到 $V_\pi(s)$。
图7: 状态价值与动作价值的关系。给定 $Q_\pi(s,a)$ 和 $\pi(a|s)$,通过对所有动作加权求和得到 $V_\pi(s)$。
- 给定采取行动之后的所有可能状态的价值$v_{\pi}(\boldsymbol s’)$以及对应奖励$r$
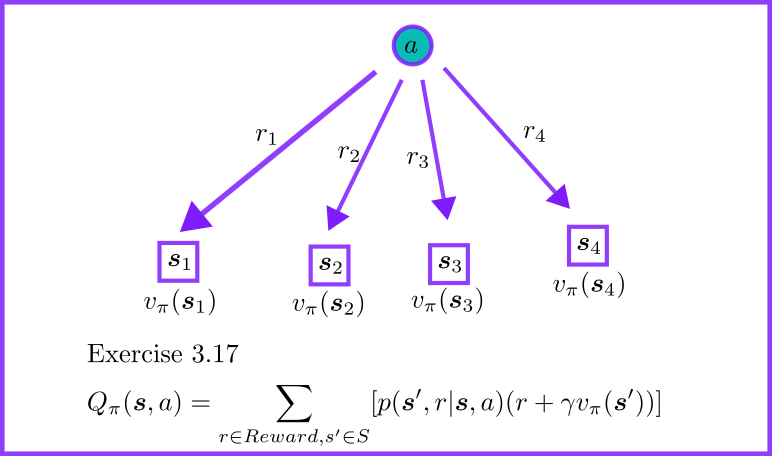 图8: 动作价值与状态价值的关系。给定 $v_\pi(s’)$ 和奖励 $r$,通过状态转移概率加权求和得到 $Q_\pi(s,a)$。
图8: 动作价值与状态价值的关系。给定 $v_\pi(s’)$ 和奖励 $r$,通过状态转移概率加权求和得到 $Q_\pi(s,a)$。
Grid World Example
这是一个简单的网格例子,可以用来展示如何利用Bellman公式迭代地计算每一个格子的$V(s)$。对于理解强化学习是如何通过迭代逐步找到价值很有帮助。再一次让我想到自举(Bootstrap).
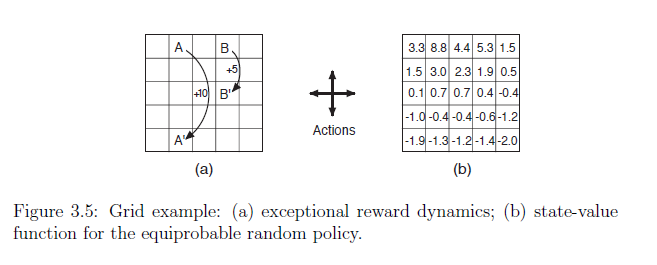 图9: Grid World 示例。5×5 网格世界,A→A’ 获得 +10 奖励,B→B’ 获得 +5 奖励,其他转移获得 -1 奖励。
图9: Grid World 示例。5×5 网格世界,A→A’ 获得 +10 奖励,B→B’ 获得 +5 奖励,其他转移获得 -1 奖励。
文章中提到,$A$格子的value小于10,$B$格子的value大于5,是因为从$A$格子出发到达的$A’$在边缘,很容易就掉出格子区域。而$B$格子的value大于5,是因为从$B$格子出发到达的$B’$在中间,不容易掉出格子区域。这里的理解就是value的估计其实是一个对后续所有可能性的综合考量,更加接近于人站在当下对未来的局势进行判断,判断出来的态势用价值函数来表示。
迭代过程展示了$V(s)$是如何利用reward逐步逼近最终价值的
因为是迭代计算,整个公式给出的绝对数据其实只有条件概率和奖励(Reward), 其实我们期望的是在经过尽可能少的迭代计算之后,就可以把最终的value收敛。
下面的动图是经过30次迭代,每个格子的value的变化走势。可以看到当前的policy下,格子的取值很快就会收敛到稳定。
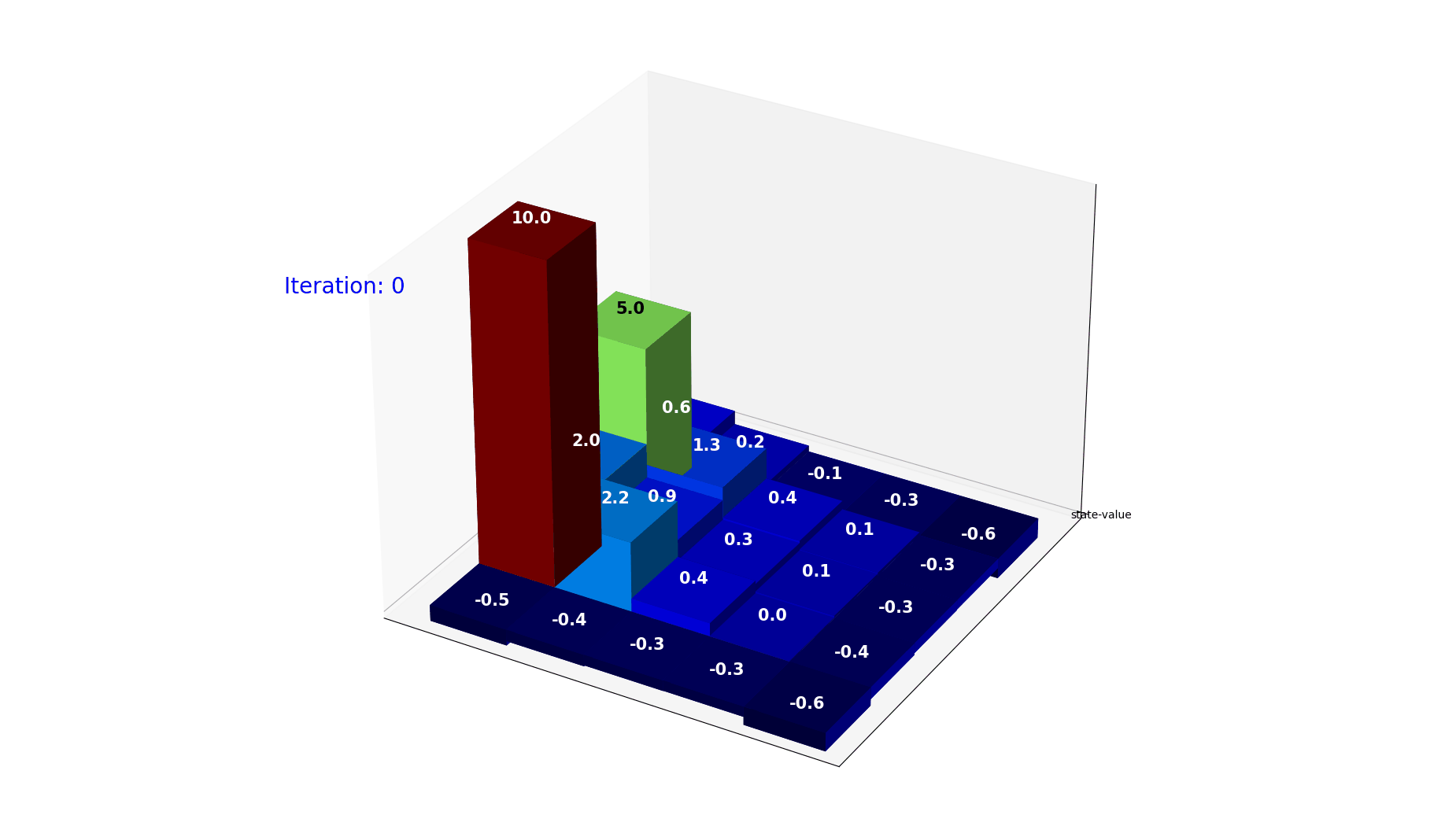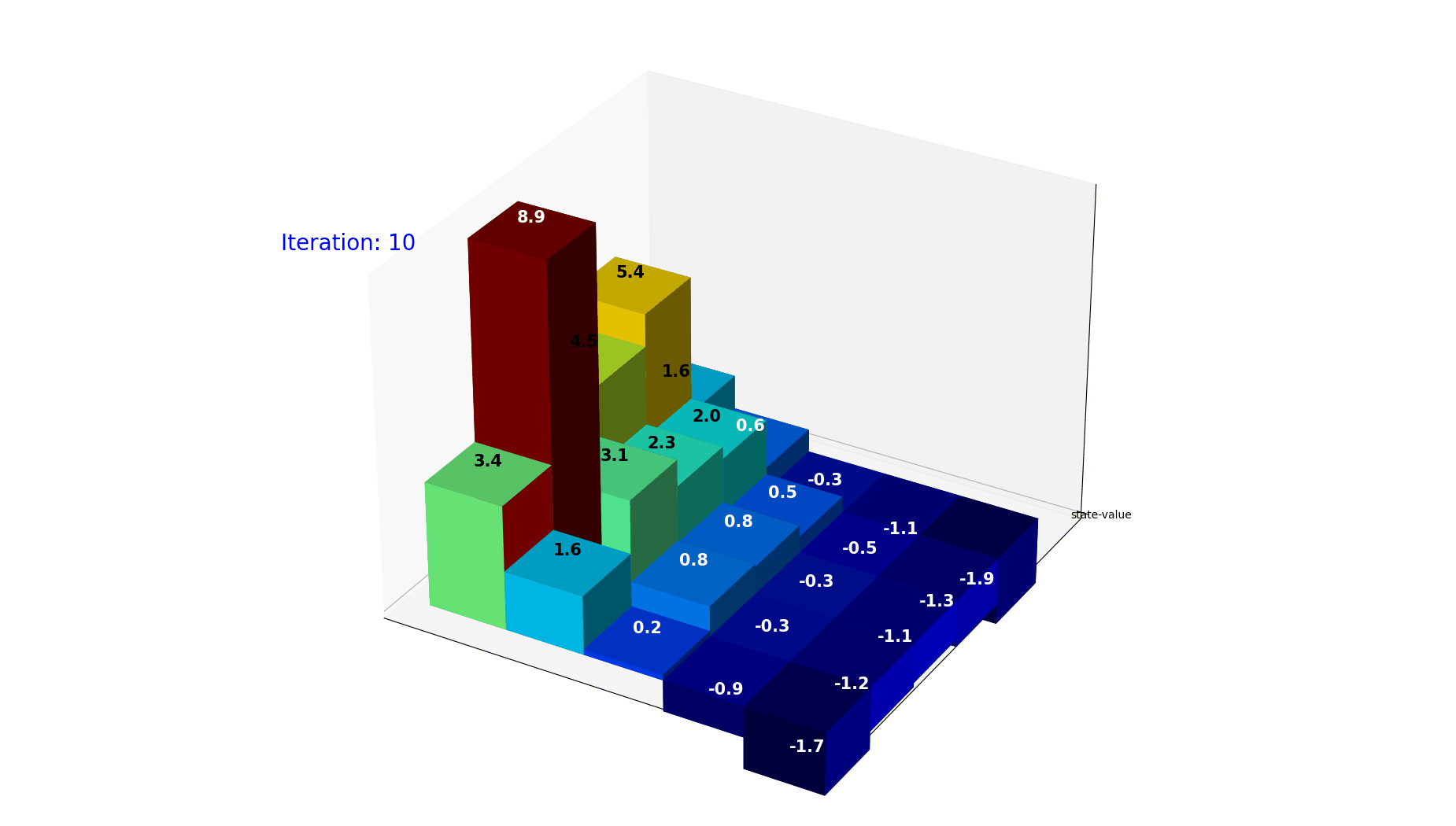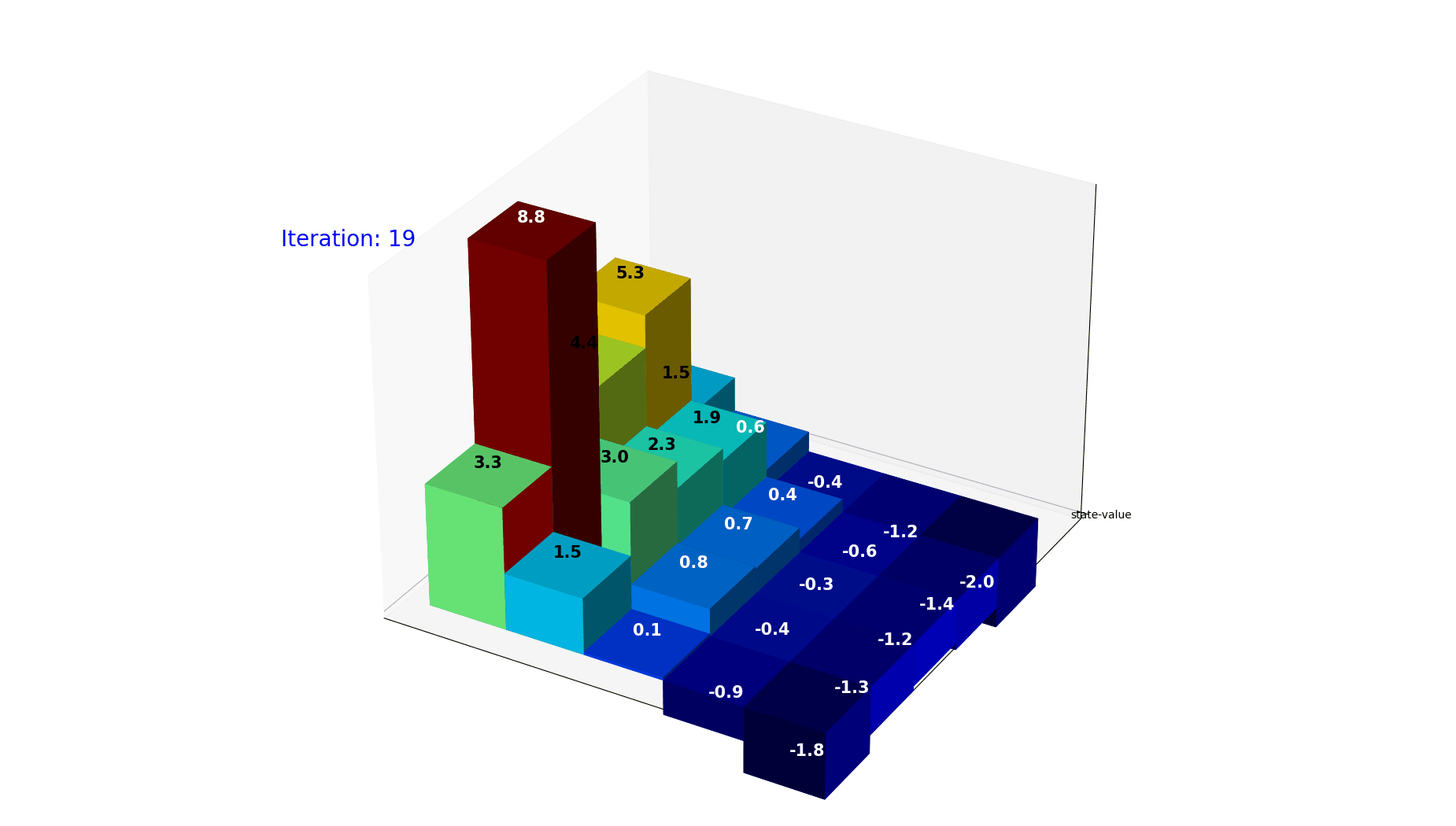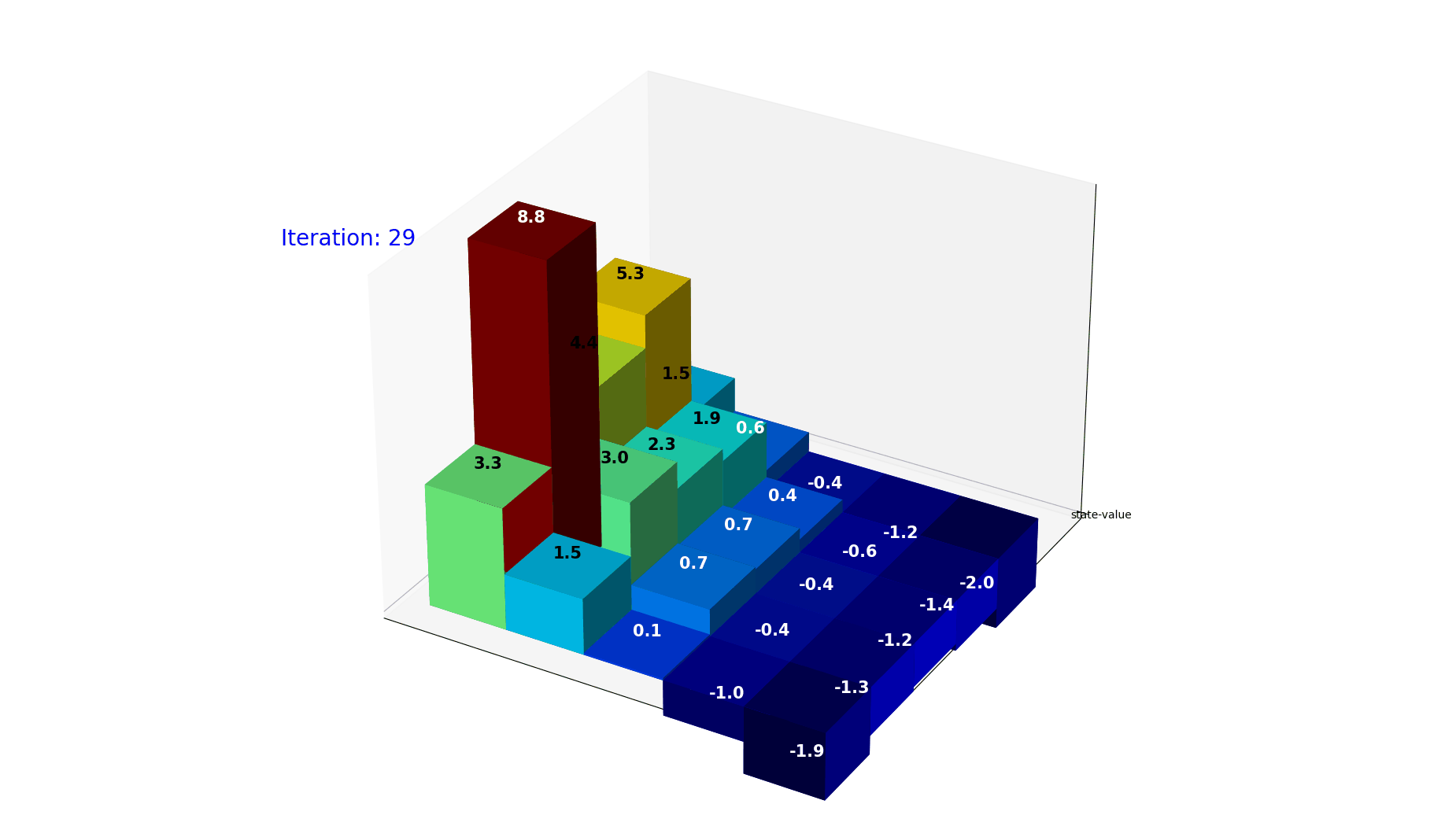 图10: 状态价值迭代收敛过程。经过 30 次迭代,各格子的 value 逐渐收敛到稳定值。
图10: 状态价值迭代收敛过程。经过 30 次迭代,各格子的 value 逐渐收敛到稳定值。
Optimal Grid World Policy
还是以网格世界为例,本章节并没有详细讨论采用什么样的算法来寻找最优的策略,这是后面章节需要讨论的问题,但是直接给出了最优的策略,参考最优策略和最优价值函数章节,如下图所示。
代码实现中, getOptimalPolicyDirections(row, colunm)其实就是最优策略的编码(图11 的c),方便在使用Bellman公式时候,调用。
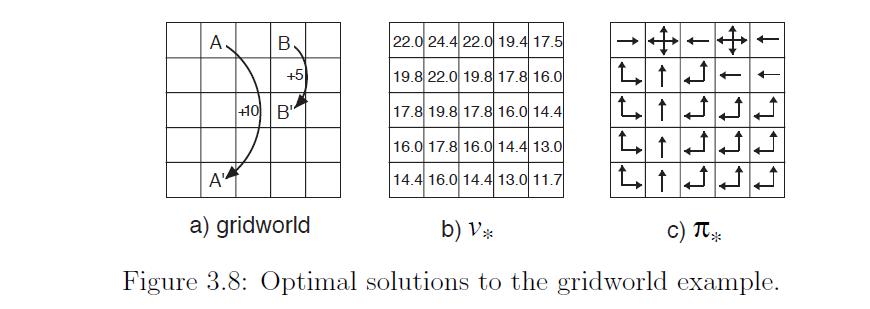 图11: 网格世界最优策略示意。最优策略 $\pi_\star$ 在每个格子选择使 $q_\pi(s,a)$ 最大的动作。
图11: 网格世界最优策略示意。最优策略 $\pi_\star$ 在每个格子选择使 $q_\pi(s,a)$ 最大的动作。
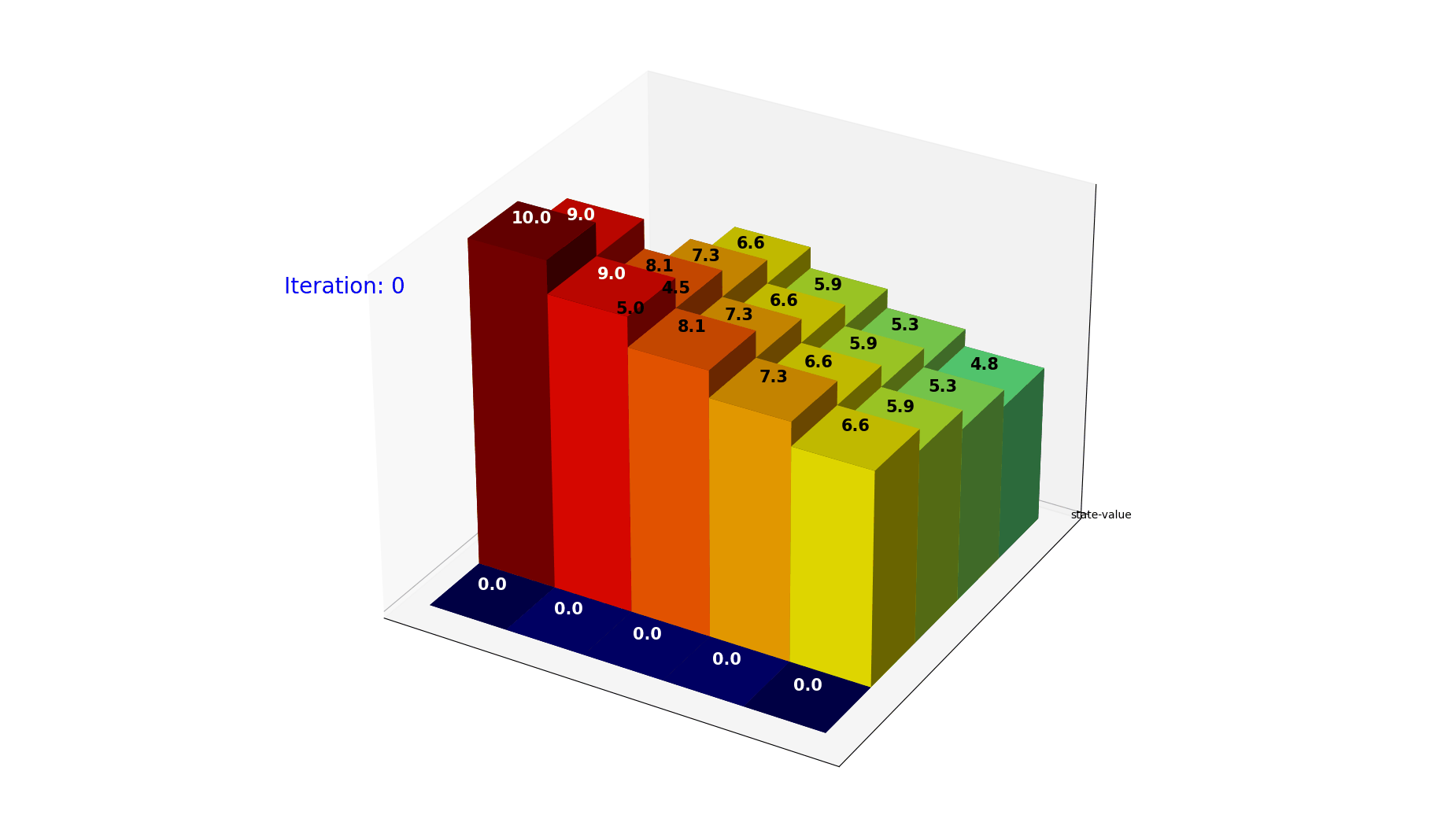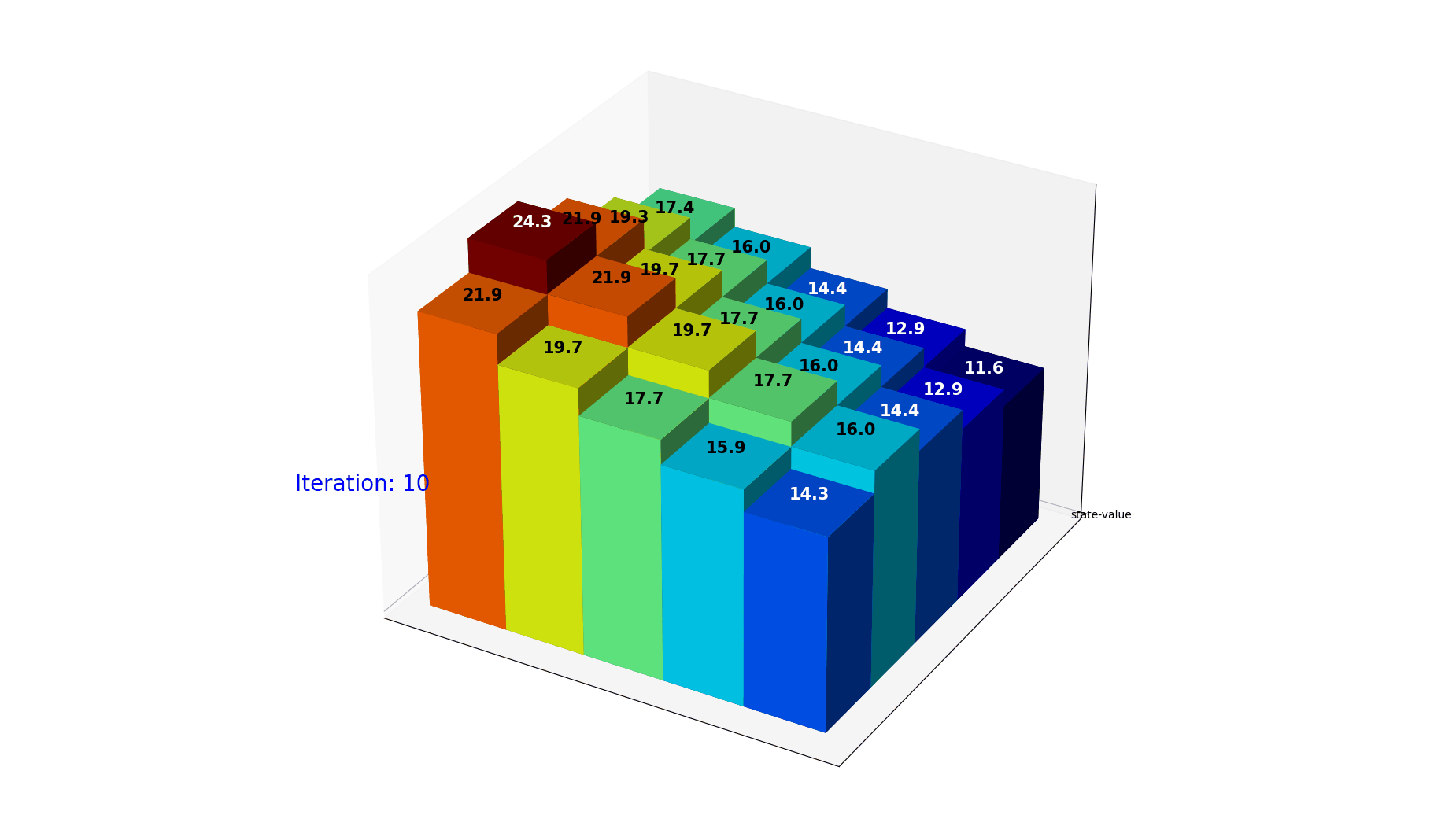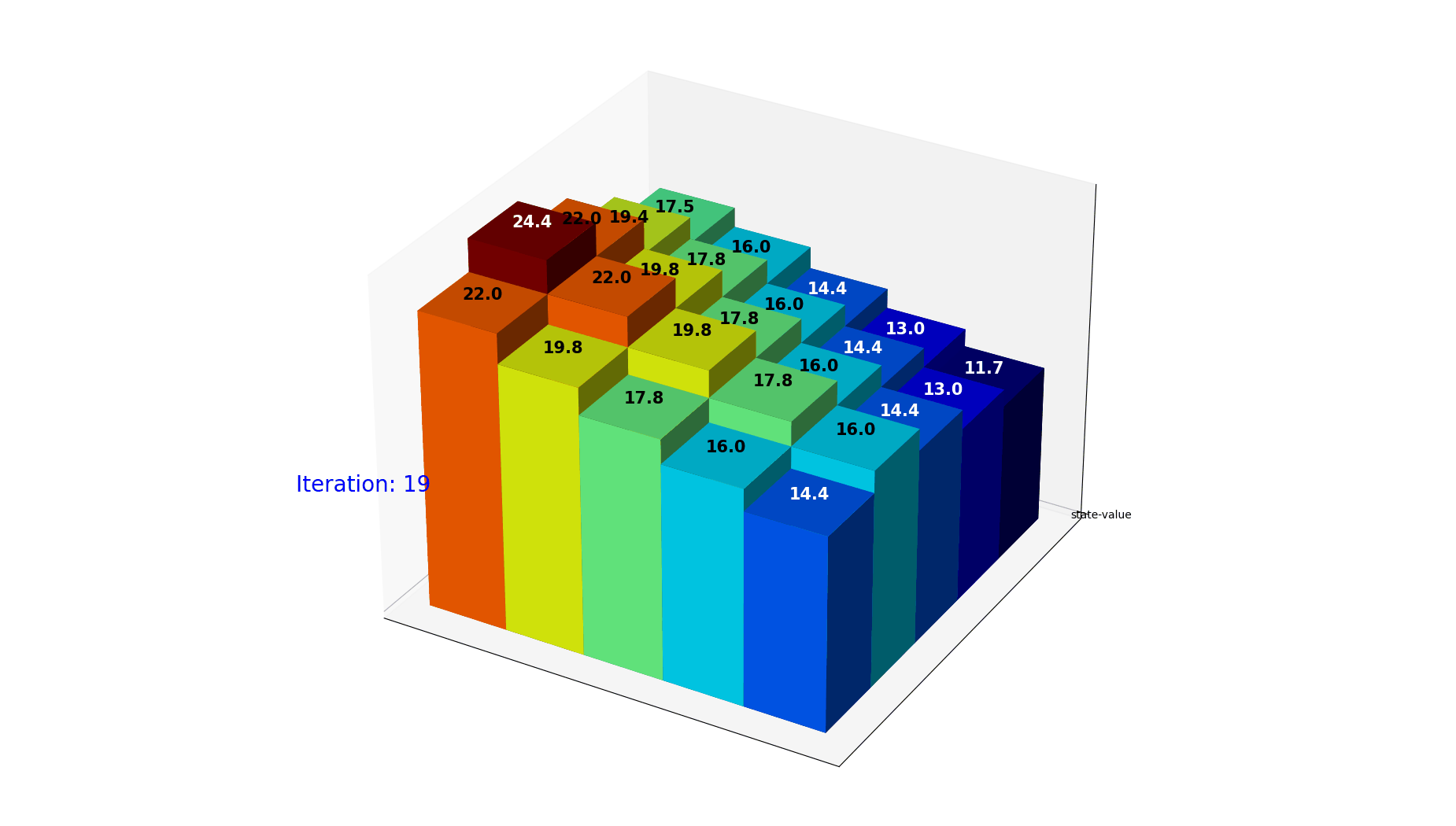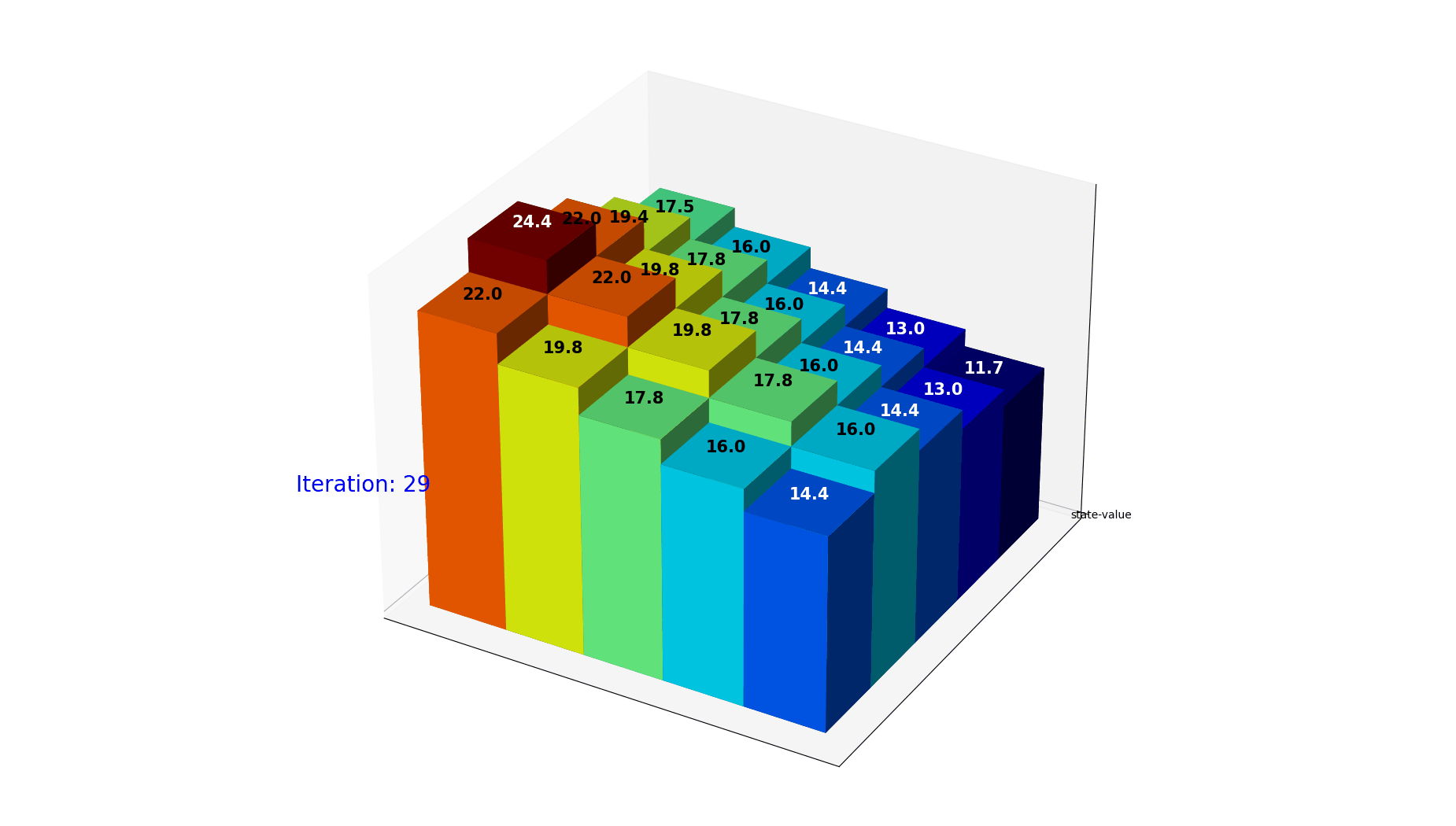 图12: 最优策略下的状态价值迭代过程。使用贪婪策略 $\pi(s) = \arg\max_a Q(s,a)$,价值快速收敛。
图12: 最优策略下的状态价值迭代过程。使用贪婪策略 $\pi(s) = \arg\max_a Q(s,a)$,价值快速收敛。