随机过程的模型建立
一般地,我们研究的随机过程是一个动态的系统(Dynamical Systems).
$$ \frac{d\boldsymbol{x(t)}}{dt}=f(\boldsymbol{x}(t),t,\beta) $$
其中,$\beta$是系统中设置的参数,$x(t)$是状态向量,加入时间$t$作为参数代表状态向量的取值随时间变化。
为了简化我们对系统的建模,首先把时间和系统参数对系统迭代的影响忽略掉,简化上面的等式:
$$ \frac{d\boldsymbol{x}(t)}{dt}=f(\boldsymbol{x}(t)) \label{eq1}\tag{1} $$
($\ref{eq1}$)是连续系统的描述,更常见的是离散系统,我们把时间离散化,得到:
$$ \boldsymbol{x}_{k+1}=F(\boldsymbol{x}_k) \label{eq2}\tag{2} $$
上面的等式仍然不是很理想,因为经常性的,$F$是一个非线性的函数,对计算机来说,很难迭代地处理这样的函数,而且我们也很难给出$F$准确的函数表达式。
那么,需要对($\ref{eq2}$)进行改写,在改写的过程中,考虑控制量的引入$\boldsymbol{u}$,如果系统建模方程中有高阶的导数,可以通过定义新的高阶导数作为变量组成维数更多的状态向量来降低阶数,最终得到个一阶的微分方程。这里具体怎么做就不展开了,并不属于这篇文章的重点内容,我们先直接使用结论。
$$ \boldsymbol{\dot x}=A\boldsymbol{x}+B\boldsymbol{u}+\boldsymbol{w} \label{eq3}\tag{3} $$
($\ref{eq3}$)描述的是系统在当前状态下,下一时刻会如何改变,是一个一阶的微分方程组(因为状态向量是多维度的),但是这样的方程组也不是我们想要的,我们期望是可以根据前一时刻的状态直接线性运算得到后一时刻的预测状态。
状态转移方程
($\ref{eq3}$) 描述的是下一时刻系统状态的增长或者是变化和当前的状态有什么关系,假如没有加入人为的控制,比如,让一个倒立摆自由运动,不提供平衡的直线运动单元,那么这个系统的一些特性,比如可控性,稳定性都可以通过研究$A$的特征值和特征向量来快速得到。 加入人为的控制量$\boldsymbol{u}$可以改变系统的特性,按照我们的期望来改造,Brunton老师说得是manipulate。在动态系统的控制领域,对矩阵$A$的研究会更多,$A$的学术用语为动态系统矩阵(System Dynamics Matrix),在状态估计领域,我们对状态转移方程更关心。实际系统经常是非线性的,但是在局部我们可以线性化。目前,从一阶微分方程组如何推导出状态转移方程是本次不讨论的内容,但是是有若干种技术去实现。
$$ \boldsymbol{x}_{k+1}=F\boldsymbol{x}_k+B\boldsymbol{u}_k + \boldsymbol{w}_k \label{eq4}\tag{4} $$
($\ref{eq4}$)中的$F$叫做状态转移矩阵(State Transition Matrix)。
非线性的系统状态转移矩阵是根据系统的雅可比矩阵来确定的,每次迭代都会变。后续需要确认是不是这样。
到目前为止,根据系统的物理定律我们在没有测量的状态下得到系统状态是如何迭代的,但是需要注意($\ref{eq4}$)中的$\boldsymbol{w}_k$:系统噪声。随着时间迭代,我们仅仅使用状态转移方程估计系统状态会越来越不准,因为描述状态的协方差矩阵$Q$会变大。
随机过程的贝叶斯后验概率分布推导
根据第一讲贝叶斯滤波的基本思路,系统迭代的过程中,需要有测量数据做融合,从概率论角度讲就是测量数据$\boldsymbol{Y}$作为随机变量,根据传感器的特性,它的似然概率分布是已知的:$P(Y<y|X)$,那么在预测步骤之后,有状态向量的先验分布$P(X<x)$,那么我们的目标是得到基于两者的后验分布。
在推导之前,需要非常明确这几条:
- 状态向量迭代的过程虽然是离散的,例如$T_1$, $T_2$时刻的状态,但是在某一时刻的取值仍然是连续的随机变量,我们在第一篇里面得到的结论仍然适用于某一时刻的情况。
- 在不同的时刻下,先验、后验分布都在变化,先验分布变化是因为系统因为物理、化学等规律随之前的状态产生了新的变化 – 就是由状态转移方程描述的。
后面的公式当中,$f_0(X)$表示在$T=T_0$时刻也就初始时刻的概率密度函数,$P(X_1<x)$是第一次迭代之后的先验概率分布函数,$P(X_1<x|Y_1=y)$是融合了似然概率之后的后验概率分布函数。
状态转移的概率分布推导
第一个需要推导的是如何根据$P(X_0<x)$和($\ref{eq4}$)推导$P(X_1<x)$ 重写($\ref{eq4}$):
$$ X_{k+1}=FX_k+Bu_k+W_k \label{eq5}\tag{5} $$
($\ref{eq5}$)可以理解成对随机变量进行逻辑运算,后面会使用到。
对$P(X_1<x)$进行全概率公式展开:
$$ P(X_1<x)=\lim_{\epsilon \to 0} \Sigma_{a=-\infty}^{a=x} P(a<X_1<a+\epsilon) \label{eq6}\tag{6} $$
$$ \lim_{\epsilon \to 0}P(a<X_1<a+\epsilon)=\lim_{\epsilon \to 0}\int_{v=-\infty}^{v=\infty} P(a<X_1<a+\epsilon|X_0=v)f_{X_0}(v)dv \label{eq7}\tag{7} $$
到这里很容易迷茫不知道怎么办,看$P(a<X_1<a+\epsilon|X_0=v)$这个条件概率,$X_1$和$X_0$肯定是相关的,因为有线性变换,控制量的输入和随机的噪声输入,相关性是因为第一项还是部分项还是全部呢? 这时就需要($\ref{eq5}$)。
令$k=0$,($\ref{eq5}$)带入($\ref{eq7}$):
$$ \lim_{\epsilon \to 0}P(a<X_1<a+\epsilon)=\lim_{\epsilon \to 0}\int_{v=-\infty}^{v=\infty} P(a<FX_0+Bu_1+W_1<a+\epsilon|X_0=v)f_{X_0}(v)dv \label{eq8}\tag{8} $$
继续推导得到:
$$ \lim_{\epsilon \to 0}P(a<X_1<a+\epsilon) =\lim_{\epsilon \to 0}\int_{v=-\infty}^{v=\infty} P(a-Fv-Bu_1<W_1<a+\epsilon-Fv-Bu_1|X_0=v)f_{X_0}(v)dv $$
这里,条件概率变为了当$X_0$取某一数值时,$W_1$保持在$(a-Fv-Bu_1, a-Fv-Bu_1+\epsilon)$的条件概率。 因为我们假设$W_1$和$X_0$相互独立,根据独立性,得到:
$$ \lim_{\epsilon \to 0}P(a<X_1<a+\epsilon) =\lim_{\epsilon \to 0}\int_{v=-\infty}^{v=\infty} P(a-Fv-Bu_1<W_1<a+\epsilon-Fv-Bu_1)f_{X_0}(v)dv \label{eq9}\tag{9} $$
($\ref{eq9}$)代入($\ref{eq6}$)得到:
$$ P(X_1<x)=\lim_{\epsilon \to 0} \Sigma_{a=-\infty}^{a=x}\int_{v=-\infty}^{v=\infty} P(a-Fv-Bu_1<W_1<a+\epsilon-Fv-Bu_1)f_{X_0}(v)dv \label{eq10}\tag{10} $$
观察($\ref{eq10}$) $\epsilon$只存在于$P(a-Fv-Bu_1<W_1<a+\epsilon-Fv-Bu_1)$当中,并且这个概率可以改写为$W_1$的概率分布$f_{W_1}(a-Fv-Bu_1)dw$,相当于在概率密度曲线和坐标横轴围成的区域上截取了很短的一段。所以一般性地,就可以将求和,取极限和微小区域的概率用积分的形式来描述:
$$ P(X_1<x)=\int_{w=-\infty}^{w=x}\int_{v=-\infty}^{v=\infty}f_{W_1}(w-Fv-Bu_1)f_{X_0}(v)dvdw \label{eq11}\tag{11} $$
概率分布函数是概率密度函数的原函数,根据微积分第一基本定理,对$x$求导得到:
$$ f_{X_1}(x)=\int_{v=-\infty}^{v=\infty}f_{W_1}(x-Fv-Bu_1)f_{X_0}(v)dv \label{eq12}\tag{12} $$
当$k>0$时,上面的推导仍然成立,需要特殊提出来的是$W_{k+1}$和$X_k$相互独立。
测量更新的概率分布推导
这里首先需要给定测量出来的向量作为随机变量$Y$和系统状态$X$之间具有如下的关系:
$$ Y=HX+V \label{eq13}\tag{13} $$
$V$是测量噪声,也当作随机变量处理。
再次列出来连续随机变量的贝叶斯公式:
$$ P(X<x|Y=y)=\int_{-\infty}^{x} \frac{f(y|u)f_X(u)}{f_Y(y)}du \label{eq14}\tag{14} $$
测量向量$Y_1, Y_2 \cdots Y_k$是不同的随机变量,它们的分布是不同的。
后验概率分布如下:
$$ P(X_1<x|Y_1=y)=\int_{-\infty}^{x} \frac{f_{Y_1|X_1}(y|u)f_{X_1}(u)}{f_{Y_1}(y)}du \label{eq15}\tag{15} $$
需要利用($\ref{eq13}$)对($\ref{eq15}$)中的似然概率和边缘概率进行推导:
首先是似然概率:
$$ f_{Y_1|X_1}(y|x)=\lim_{\epsilon \to 0} \frac{P(y<Y_1<y+\epsilon|X_1=x)}{\epsilon} =\lim_{\epsilon \to 0} \frac{P(y<HX_1+V_1<y+\epsilon|X_1=x)}{\epsilon} \label{eq16}\tag{16} $$
条件概率当中的条件可以拿来参与计算,($\ref{eq16}$)变为:
$$ f_{Y_1|X_1}(y|x)=\lim_{\epsilon \to 0} \frac{P(y-Hx<V_1<y-Hx+\epsilon|X_1=x)}{\epsilon} \label{eq17}\tag{17} $$
条件概率的条件$X_1=x$和$V_1$取值相互独立,所以去掉条件: $$ f_{Y_1|X_1}(y|x)=\lim_{\epsilon \to 0} \frac{P(y-Hx<V_1<y-Hx+\epsilon)}{\epsilon}=f_{V_1}(y-Hx) \label{eq18}\tag{18} $$
然后是边缘概率。
到这里,我最开始对于为什么需要把分母的那个边缘概率展开为全概率是不理解的,它其实就是一个不为零的常量,直接放在那里不是就可以了么?
在 Kalman and Bayes Filters in Python3.12 章节讲到了这个量叫做evidence,就是不考虑当前状态在哪里的情况下,测量值出现$y$的概率。看到这里,再仔细想一想,这样的一个概率其实是很没有根据的,还不如把所有的测量可能和在当前可能下的条件概率做全概率积分更有意义。所以有了下面的推导。
那么问题又来了,我们怎么寻找那个全概率的“基底”呢?就是上一篇文章中说的$B_1,B_2,\cdots, B_n$的样本到底是怎么样的一个概率分布呢?自然地,那个初始的$X_0$的先验分布经过了一个时间周期其实已经过时了,并不能很好地反映最新的情况,那么经过状态转移方程得到的先验概率分布更符合当前状态分布,那么可以利用这个分布和条件概率的乘积积分来计算:
$$ f_{Y_1}(y)=\int_{-\infty}^{\infty} f_{Y_1|X_1}(y|x)f_{X_1}(x)dx $$
令
$$ \xi = \frac{1}{\int_{-\infty}^{\infty} f_{Y_1|X_1}(y|x)f_{X_1}(x)dx}=\frac{1}{\int_{-\infty}^{\infty} f_{V_1}(y-Hx)f_{X_1}(x)dx} $$
得到:
$$ f_{X_1|Y_1}(x|y)=\xi f_{Y_1|X_1}(y|x)f_{X_1}(x)=\xi f_{V_1}(y-Hx)f_{X_1}(x) $$
因为在实际计算的过程中,预测步骤得到的$X_1$的新分布和预测之前其实是不一样的,并且测量更新之后的$X_1$分布也发生了变化,所以把第$k$次预测之后测量更新之前的分布写成$f_{k}^{-}(\boldsymbol{x})$,把测量更新之后的分布写成$f_{k}^{+}(\boldsymbol{x}|\boldsymbol{y})$得到最终的随机过程贝叶斯迭代公式:
$$ f_{k}^{-}(\boldsymbol{x})=\int_{\boldsymbol{v}=-\infty}^{\boldsymbol{v}=\infty}f_{W_k}(\boldsymbol{x}-F\boldsymbol{v}-B\boldsymbol{u}_k)f^{+} _{k-1}(\boldsymbol{v})d\boldsymbol{v} \label{eq19}\tag{19} $$
$$ f_{k}^{+}(\boldsymbol{x}|\boldsymbol{y})=\xi_k f_{V_k}(\boldsymbol{y}-H\boldsymbol{x})f_{k}^{-}(\boldsymbol{x}) \label{eq20}\tag{20} $$
$$ \xi_k = \frac{1}{\int_{-\infty}^{\infty} f_{V_k}(\boldsymbol{y}-H\boldsymbol{x})f_{k}^{-}(\boldsymbol{x})dx} \label{eq21}\tag{21} $$
卡尔曼滤波器
引入期望的几何意义
($\ref{eq19}$)、($\ref{eq20}$)和($\ref{eq21}$)中,每次迭代需要知道概率密度,知道了概率密度之后,还需要根据概率密度确定一个“最佳”数值,比如确定在期望的位置为最佳。这样实际工程中没办法使用,尤其是实时性很强的系统,每秒需要处理上百次数据,每次积分不现实。
Kalman在1960年发表的论文当中,首先论证了如何最小化估计和真实值之差在给定测量值条件下的期望,解就是状态在测量条件下分布的期望。
$$ \mathbb{E}(\boldsymbol{X})=\int_{-\infty}^{\infty} x f_{\boldsymbol{X}}(x)dx \label{eq22}\tag{22} $$
($\ref{eq22}$)是随机变量$\boldsymbol{X}$的期望。
论文中还讲了正交投影,把测量空间内的随机变量分解为若干个单位正交的随机变量的线性组合,定义随机变量正交需要满足乘法期望为零。所以,任意随机变量可以分解为两部分:一部分属于测量空间,一部分属于正交于测量空间。
$$ \boldsymbol{X}=\bar{\boldsymbol{X}}+\boldsymbol{X}^{\perp} $$
测量空间的表示
$\bar{\boldsymbol{X}}$,可以由如下表达式得到:
$$ \bar{\boldsymbol{X}}=\Sigma_{i=1}^{n} \mathbb{E}(\boldsymbol{X}e_i)\boldsymbol{e}_i \label{eq23}\tag{23} $$
($\ref{eq23}$)中的期望部分就是对随机变量$\boldsymbol{X}$向$\boldsymbol{e}_i$做投影得到的系数$a_i$。
正交空间的表示
论文中证明了在正交空间内的任意随机变量,都和测量空间内的随机变量正交,下面的符号代表了正交空间内的随机变量: $$ \boldsymbol{X}^{\perp} $$
状态变量的最优估计就是向测量空间做正交投影得到的新的随机变量
论文中证明了这一点。在阅读论文的过程中,我发现,推导过程和模型很类似于最小二乘法在向量空间中的推导,所以下面的描述是对照最小二乘和随机变量的最优估计来进行。
在我之前的一篇文章《投影矩阵和最小二乘》中,已知空间当中的一些点,如何找到一条直线使得这条直线到每一个已知点的距离最小,这个问题和现在的随机变量估计问题有很深的类似关系。
- 给定的已知点就是这里的测量,而且不同时刻$k$的测量$\boldsymbol{Y}$这个随机变量才对应于最小二乘里面的点
- 最小化一个目标函数,在最小二乘当中,最小化的是误差绝对值的求和,在这里最小化的是估计出来的随机变量$\boldsymbol{X}$和真实值$\boldsymbol{X}$的差的损失函数的期望,文中提到最常见的损失函数是二次方的$L(\epsilon)=\epsilon^2$
- 最小二乘当中,为了求出那条直线,需要确定两个参数$a$和$b$,在二维空间正好参数的确定和描述一个点$(x,y)$所需要的维度相同,矩阵$M$的列向量所形成的空间对应的是这里测量空间
- 如果随机变量$\boldsymbol{X}$、$\boldsymbol{Y}$期望都是0,这里最小化损失函数的期望所对应的最优估计(Optimal Estimation)就是当前的随机变量$\boldsymbol{X}$向测量空间做投影得到$\bar {\boldsymbol{X}}$,对应于最小二乘中使用投影矩阵对向量$\boldsymbol{y}$左乘得到投影向量$\boldsymbol{y}_{projection}$
- 得到了投影之后的随机变量$\bar {\boldsymbol{X}}$通过($\ref{eq23}$)就可以得到对应的参数。
论文当中的演进思路
Optimal Estimates: 给定了一组测量值,如何最优估计出来带有噪声的测量值所测量的状态向量?Wiener指出状态估计问题就是需要使用概率理论和统计的方法来解决。论文当中的定理1,说的是对状态向量的最优估计(最优的意义是把估计量和实际量做差当作一个随机变量,然后对该变量求loss 一般是$L(\epsilon)=\epsilon^2$)等价于状态向量在出现测量的条件下的期望。就是说,首先,我们需要搞清楚这个条件概率的分布,其次,把这个分布的期望当作最终的估计量–符合我们对事情的认知,因为我们经常通过求平均数来获取一个数据更加准确的估计。求期望,其实就是统计平均。
Orthognal Projection: 讲的是给定一组测量值$y(t_1),y(t_2),\cdots, y(t_k)$且这些测量向量的元素一一对应状态向量中的元素,且$x(t)$和$y(t)$是期望为0的正态分布随机变量,在这些测量的条件下的最优估计是状态正交投影到测量空间得到的投影向量。但是到目前,我们仅仅是知道投影向量一定是测量值的线性组合(因为对那些basis– $e_i$做投影得到的系数和对具体的测量值做投影得到系数,虽然具体的系数不一样,但是组合起来都代表同一个向量,具有等效性,而且测量值是直接得到的数据,为了方便,那么就直接使用测量值的线性组合来取代basis的线性组合),但是不知道具体的系数。 $$ \bar x(t_1|t)= x^\star(t_1|t)=\hat{E}[x(t_1)|\mathcal{Y}] $$ 因为卡尔曼滤波以实现简单著名,一个重要的原因是它不需要记录历史的所有观测就可以做最优估计,但是到目前为止,我们还不知道怎么迭代性地使用上面的结论。
Models For Random Processes: 讲的是对系统进行建模,最理想的情况是首先定义了一个时间原点,然后根据当前时间作为输入给出我们关心的系统输出和时间的数学表达式。这样的方法在实际应用当中不方便,人们更多关注的是基于现在的已知情况,求出当前情况下的系统输出是什么样子(状态转移方程)或者系统变化了多少(一阶微分方程),不管是前面的哪种,都属于一个迭代的描述,从而有了有一阶的微分方程,如果系统是线性的,可以把微分方程写成状态转移方程。但是,尽管我们可以得到状态转移方程,在实际应用当中,无法忽视系统迭代过程中噪声模型,人们也不可能列举所有可能的输入下系统输出的分布情况,但是人们可以统一做一组实验,就是在单位阶跃的输入下,系统随着时间如何变化,或者在均值为0的高斯扰动下,系统产生的输出的不确定度,这个不确定度使用了$Q(t)$来表示。需要指出的是,在实际应用中,我们的输入信号已经具有了一定的不确定度,就是$P(t)$,那么经过系统之后,输出的不确定度其实是变大的,也就是论文中公式(24)所要表达的内容。
Solution Of the Wiener problem: 讲的是从系统迭代的角度,在有状态转移方程、过程噪声协方差矩阵、测量向量和测量噪声协方差矩阵情况下,如何求解系统状态的最优估计。99%的情况下,新得到的测量值一定是携带了新的有用信息,从数学的角度来看,就是这个$y(t)$一定不在原有的$\mathcal{Y}(t-1)$空间内,如果系统运转仍旧保持连续的话,大概率主要部分仍然在$\mathcal{Y}(t-1)$内,少部分在$\mathcal{Y}(t-1)$正交空间内。方法是把$x(t+1)$状态向量(经过当前次系统的输出)对$Y(t)$的条件期望改写为对$Y(t-1)$和$Z(t)$(新增测量向量与$\mathcal{Y}(t-1)$形成的正交空间)的条件期望之和(因为两个空间正交,且两个空间合起来组成的manifold和$\mathcal{Y}$代表的manifold是完全一样的。那么对$\mathcal{Y}$的条件期望就等于分别对这两个正交空间求条件期望再相加),根据论文之前的所描述的,最后得到一个$n\times p$的矩阵$\Delta^\star(t)$ 就得到了卡尔曼增益矩阵。这个矩阵本质上是把新增的这个正交空间内的有用信息加进来形成在全观测下的最优估计。但是到这里,如何计算这个增益矩阵是不知道的,后面根据过程噪声和测量噪声推导卡尔曼增益。
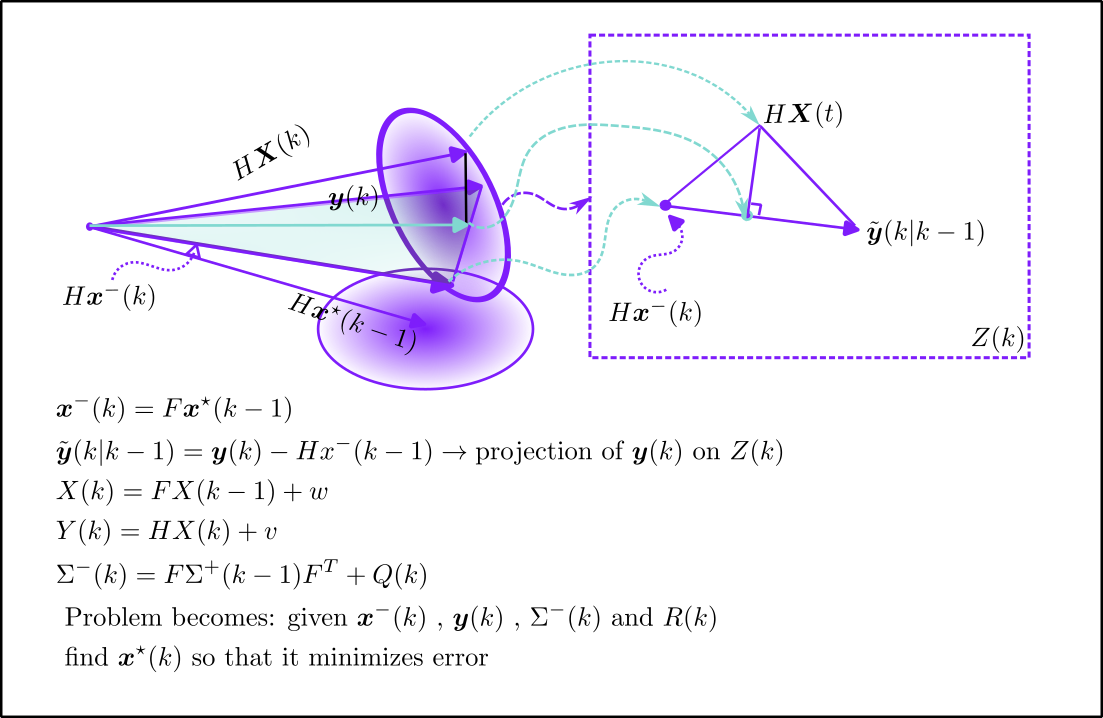
这一步就是需要计算出卡尔曼增益矩阵的具体表达式。因为卡尔曼增益是$Z(t)$空间内的向量的线性组合系数,公式(18)表述的最优估计取决于预测和测量两个过程的准确性。直觉上,如果过程噪声小,测量噪声大,那么,最优估计就更接近预测,反之,更接近于测量。 论文中公式(25)卡尔曼增益为什么要那样计算我不明所以,但是我觉得作者心里有一个直观的图形指导他如何推导的。 有必要把前面说的两个噪声画出来,形象理解。经过参考另外一篇论文,卡尔曼滤波的几何解释,作者把状态分为两部分,一部分是观测可以直接测量到的,另一部分是观测无法直接测量的。
我理解的计算过程如下图:图中灰色椭圆代表了新的测量引入的额外信息$\mathcal{Z}(t)$流形,与蓝色的$\mathcal{Y}(t-1)$正交。因为上一时刻的最优估计$x^{\star}(t)$位于$\mathcal{Y}(t-1)$中,预测时候得到的预测量$\Phi(t)x^{\star}(t)$仍然在$\mathcal{Y}(t-1)$中。但是根据状态转移方程,实际的状态受到$u(t)$的干扰,并不会严格位于$\mathcal{Y}(t-1)$,如图中红色箭头所示。借助于$\mathcal{Z}(t)$,这个流形正交于$\mathcal{Y}(t-1)$(实在是难以画出来),我们手里掌握的信息:预测$M\Phi(t+1;t)\boldsymbol{x}^{\star}(t-1)$(黑色向量),预测噪声$u(t)$和预测向量协方差$\Phi P^{\star}(t)+Q(t)$(黑色虚线),测量噪声$\boldsymbol{v}(t)=M\boldsymbol{x}-\boldsymbol{y}$协方差$R$(绿色虚线),**因为当前次的测量决定了最终的结果的投影必然在橙色的直线上,所以问题就转化成了如何根据可测部分和不可测部分,在橙色直线上找到一个点,使得这个点距离红色点最近。**很容易知道:过红色点向橙色虚线做垂线,垂足位置就是可观测部分到红色点的最近点,再根据不可观测部分的状态转移方程,不可观测的向量并不完全落入$\widetilde y(t|t-1)$,但是其中的$\widetilde {x}_{2p}(t|t-1)$分量是相关的部分,再次对这一部分做垂线得到的点就是不可观测部分的分量。从而我们找到了第$(t+1)$次的最优估计。
首先需要明确的是测量误差和经过预测的可观测部分和测量值之间的误差是不同的。
2025-06-04
Geometric illustration of the Kalman filter gain and covariance update algorithms
下图左侧,$\boldsymbol y(k)$(最新的测量向量)和$H\boldsymbol x^-(k)$(经过系统模型的预测量)所形成的平面(其实是流形),需要在该平面上找到一个$k$时刻的最优估计,使得估计误差最小。到这里,问题就应该描述清楚了,其实跟卡尔曼滤波和最小二乘的关系的思路是一样的,只不过经过系统的迭代之后,所形成的要投影的量测空间发生了改变。
原始论文当中,其实并没有提到从几何的角度理解,但是重点强调了垂直于$\mathcal Y(k-1)$空间的$\mathcal Z(t)$空间:下图右侧的虚线矩形框。
最优估计一定要落在$\tilde {\boldsymbol y}(k|k-1)$上面吗?答案是一定的。首先,基于系统和基于测量,我们得到的是两个具体的向量,这两个向量一定是带噪声的,那么,我们很清楚地知道:真实的状态一定是悬在这两个向量之外的某个地方,虽然不确定,但是根据$\mathbb{E}[\boldsymbol X(k) - \boldsymbol x^-(k)][\boldsymbol X(k) - \boldsymbol x^-(k)]^T=\Sigma^-(k)$和$\mathbb{E}(\boldsymbol v\boldsymbol v^T)=R(k)$,原始论文推导到公式(18)的时候,很明确地得出:新的测量带来新的那部分空间,对于状态的更新部分就是$\mathbb{E}(\boldsymbol x|\mathcal Z(t))$,那么,两个空间(平面)相交所形成的交线就是量测在新空间的更新部分$\tilde {\boldsymbol y}(k|k-1)$
问题变为如何在已知一个点和一条线段的前提下,求出点到线段的最短距离–这个距离体现的就是卡尔曼估计的状态更新误差$\boldsymbol e =\boldsymbol X(k) - \boldsymbol x^\star(k)$
适当理解右图的三角形:当三角形左边直角边变短(系统模型更精确):卡尔曼估计偏向系统的预测;当三角形右边直角边变短(测量噪声更小):卡尔曼估计偏向测量。
卡尔曼增益是从三角形左下顶点到垂足的线段和整个斜边的比例。
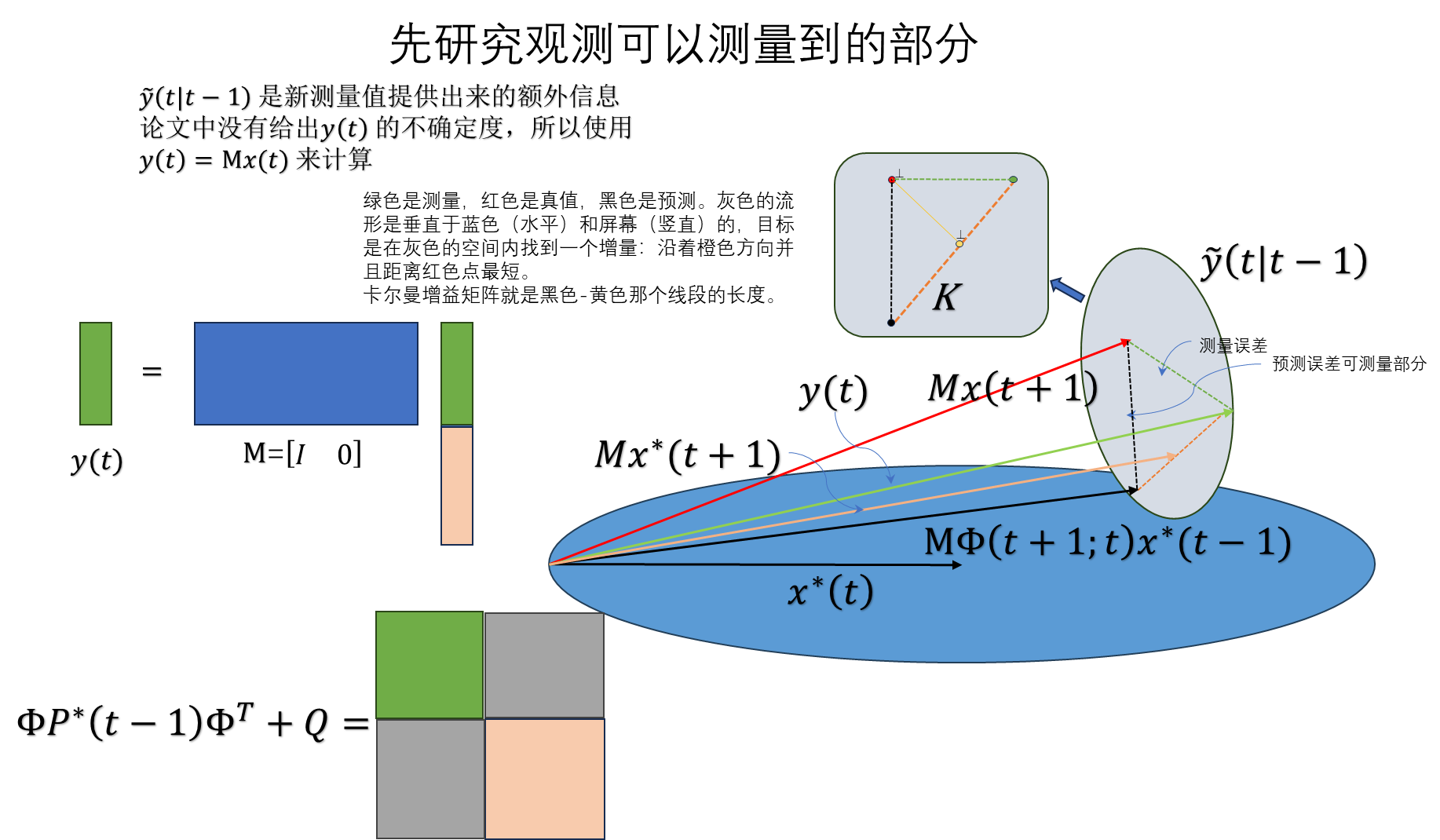
续2023-12-08:
$$ \widetilde{y}(t)=y(t)-M\Phi(t)x^{\star}(t-1) $$
可以用简单的几何关系来推导一下:
$$ \frac{|| \widetilde x_1(t|t-1) || }{||\widetilde{y}(t)||}=\frac{K_1 ||\widetilde{y}(t)||}{|| \widetilde x_1(t|t-1) ||} $$
推出:
$$ K_1=\frac{|| \widetilde x_1(t|t-1) ||^2}{||\widetilde{y}(t)||^2} $$
不可观测部分:
$$ \frac{K_2||\widetilde{y}(t)||}{||\widetilde{x}_{2p}||}\frac{||\widetilde{x}_1||}{||\widetilde{y}(t)||} $$
推出:
$$ K_2=\frac{||\widetilde{x}_{2p}||\times||\widetilde{x}_1||}{||\widetilde{x}_1||} $$
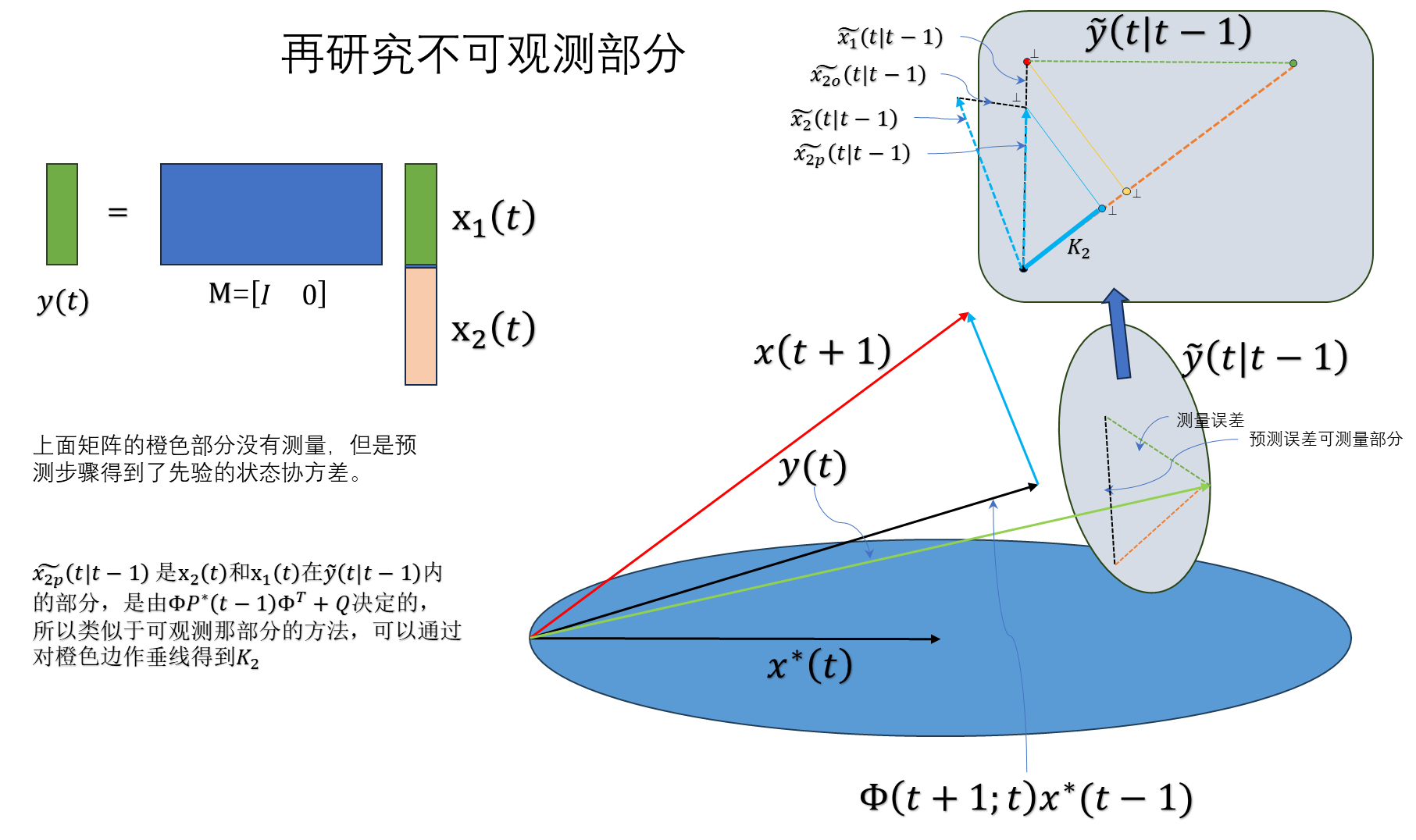
有了直观的几何理解,后面的具体推导部分,就比较容易理解和建立对应关系了。
具体的推导过程
就是假设随机变量的分布是高斯的,也叫做正态分布,这个分布有如下的特性:
- 使用$\mu$表示期望,$\sigma$表示方差,两个参数可以完全描述一个高斯分布
- 假设过程噪声$\boldsymbol{W}_k\sim N(0, Q_k)$,测量噪声$\boldsymbol{V}_k\sim N(0, R_k)$,两个随机变量期望均为0,协方差矩阵为$Q_k$和$R_k$
所以过程噪声的概率密度函数写为: $$ f_{\boldsymbol{W}_k}(w)=\frac{1}{\sqrt{2\pi Q_k}}e^{-\frac{1}{2}w^TQ_k^{-1}w} $$
测量噪声的概率密度函数写为:
$$ f_{\boldsymbol{V}_k}(v)=\frac{1}{\sqrt{2\pi R_k}}e^{-\frac{1}{2}v^TR_k^{-1}v} $$
由于我们需要从第$k$次开始迭代推导,需要首先明确的是状态变量$\boldsymbol{X}^{+}_{k-1}$符合什么样的分布?根据论文的描述,在两个前提条件下:
(1)随机变量$\boldsymbol{X}$和$\boldsymbol{Y}$是高斯的,具体说来就是($\ref{eq4}$)中的$\boldsymbol{w}_k$是期望为0,协方差矩阵为$Q_k$的高斯分布,($\ref{eq13}$)中的$\boldsymbol{v}_k$是期望为0,协方差矩阵为$R_k$的高斯分布。
(2)最优估计当中的损失函数定义为$L(\epsilon)=\epsilon^2$,第$k-1$次的最优估计是就是$\boldsymbol{Y}$所在空间的基的线性组合,因为这个空间内的基是满足高斯的,所以高斯的线性组合仍然为高斯的:$\boldsymbol X _{k-1} \sim N( \boldsymbol \mu _{k-1}^+ , \Sigma _{k-1} ^+)$
根据($\ref{eq19}$)推导先验概率密度:
$$ f _{k}^{-}(\boldsymbol{x})=\int _{\boldsymbol{v}=-\infty}^{\boldsymbol{v}=\infty}f _{W_k}(\boldsymbol{x}-F\boldsymbol{v}-B\boldsymbol{u}_k)f _{k-1}^{+}(\boldsymbol{v})d\boldsymbol{v} $$
高斯分布概率密度函数代入:
$$ f _{k} ^{-}(\boldsymbol{x})=\int _{\boldsymbol{v}=-\infty}^{\boldsymbol{v} =\infty}\frac{1}{\sqrt{2\pi Q_k}}e ^{-\frac{1}{2}(\boldsymbol{x}-F\boldsymbol{v}-B\boldsymbol{u}_k)^TQ_k^{-1}(\boldsymbol{x}-F\boldsymbol{v}-B\boldsymbol{u}_k)}\frac{1}{\sqrt{2\pi \Sigma _{k-1}}}e ^{-\frac{1}{2}(\boldsymbol{v}-\boldsymbol{\mu} _{k-1})^T\Sigma _{k-1}^{-1}(\boldsymbol{v}-\boldsymbol{\mu} _{k-1})}d\boldsymbol{v} $$
上面的推导得到结果:$\boldsymbol{X}^-_k \sim N(F\boldsymbol{\mu} _{k-1}^+ +B\boldsymbol{u} _k, F\Sigma _{k-1}^+F^T+Q_k)$
$$ \boldsymbol{\mu} _k^- =F\boldsymbol{\mu} _{k-1}^+ +B\boldsymbol{u}_k \label{eq24}\tag{24} $$
$$ \boldsymbol{\Sigma} _k^-=F\Sigma _{k-1}^+F^T+Q_k \label{eq25}\tag{25} $$
- 根据($\ref{eq20}$)推导后验概率密度:
$$ f_{k}^{+}(\boldsymbol{x}|\boldsymbol{y})=\xi_k f_{V_k}(\boldsymbol{y}-H\boldsymbol{x})f_{k}^{-}(\boldsymbol{x}) $$
$$ f_{k}^{+}(\boldsymbol{x}|\boldsymbol{y})=\xi_k \frac{1}{\sqrt{2\pi R_k}}e^{-\frac{1}{2}(\boldsymbol{y}-H\boldsymbol{x})^TR_k^{-1}(\boldsymbol{y}-H\boldsymbol{x})}\frac{1}{\sqrt{2\pi \boldsymbol{\Sigma}^-_k}}e^{-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu}^-_k)^T(\Sigma^-_k)^{-1}(\boldsymbol{x}-\boldsymbol{\mu}^-_k)} \label{eq26}\tag{26} $$
($\ref{eq26}$)推导得到结果:$\boldsymbol{X}^+_k \sim N(\boldsymbol{\mu}^+_k, \Sigma^+_k)$
$$ \boldsymbol{\mu}^+_k=\boldsymbol{\mu}^-_k+K_k(\boldsymbol{y}-H\boldsymbol{\mu}^-_k) \label{eq27}\tag{27} $$
$$ \Sigma^+_k=(I-K_kH)\Sigma^-_k \label{eq28}\tag{28} $$
$$ K_k=\Sigma^-_kH^T(H\Sigma^-_kH^T+R_k)^{-1} \label{eq29}\tag{29} $$
- 卡尔曼滤波的五个公式。
($\ref{eq24}$)、($\ref{eq25}$)、($\ref{eq27}$)、($\ref{eq28}$)和($\ref{eq29}$)就是卡尔曼滤波的向量形式。黑体小写符号代表了向量,大写代表了矩阵。
卡尔曼滤波和最小二乘的关系
2025-5-29
最小二乘解决的是已知空间中有很多点,如何找到一条直线,能够保证这条直线到给定的所有点的距离最短,具体问题的形成过程参考上面的链接。
卡尔曼滤波解决的是:已知历史上很多的观测点,如何得到待估计的状态的最合理的值,这个最合理,Kalman定义出一个loss function,就是实际上的状态(Ground Truth)$X_1(t_1)$和我们自己找到的估计状态$x_1(t_1)$之间的差距: $$ \epsilon=x_1(t_1) - X_1(t_1) $$ loss function: $L(\epsilon)$
接下来的问题是,最小二乘里面,点是确定的,但是滤波问题里面,你手上的一堆观测点其实自己就不太准,无法按照确定的点来处理。卡尔曼老先生的思路是:
1)首先,观测$y(t)$是一个随机变量,它一定满足某种分布$D$ – 原论文第三页左上部分。
2)状态估计$X_1(t_1|t)$是$D$的某种函数$f(D)$
3)背后有一个隐含的东西是:我们手头上拿到的观测其实代表了一个空间(这是客观存在的根本信息,比观测本身要有更好的质量,因为可以通过一些正交基$\boldsymbol e_1 \boldsymbol e_2 \cdots \boldsymbol e_n$来表征,其实这些基也是晃晃悠悠的,但是好消息是它们是正交的:$\mathbb{E}_{i\neq j}(\boldsymbol e_i \boldsymbol e_j)=0$),我在这里把这个空间叫做量测空间。
4)最小二乘里面最小化的是那个$\boldsymbol e$,$\boldsymbol e=\boldsymbol y - M\boldsymbol x$,但是卡尔曼先生希望最小化的是误差函数的期望$\mathbb{E}L(\epsilon)$,更准确地说应该是一个条件概率函数的期望$\mathbb{E}L(\epsilon| \text{after all the } \boldsymbol y \text{s are seen})$
5)卡尔曼先生用图形化的方法(其实就是最小二乘的模型),空间当中给定任意一个向量,其实就是待估计的状态$X_1(t_1)$的一个具体向量$x_1(t_1)$,它是一个随机变量,也是一个向量,$X_1(t_1)$不太可能完全存在于刚才提到的那个空间当中,但是!它的一部分存在,那一部分可以是很少,可以是很多,最优的估计(使得$\mathbb{E}L(\epsilon| \text{after all the } y \text{ are seen})$最小的估计)就是把$x_1(t_1)$投影到量测空间,让$x_1(t_1)$最大程度地出现在量测空间。相比于最小二乘的确定性(Deterministic),卡尔曼滤波针对不确定性所做的投影操作就是求待估计量对观测的条件概率的期望,最后落实到地面就是拿着具体活生生的向量$x_1(t_1)$做投影,投影得到的那个$\boldsymbol x_1^\star(t_1|t)$就是本次量测更新,人们就可以使用它!!!!原论的文当中公式(5)$\boldsymbol x_1^\star(t_1|t)=\mathbb{E}[x_1(t_1)|y(t_0)\cdots y(t)]$。
6)上面的描述过程,其实大部分是飘在天上~
7)如果我们联系上要研究的系统,$x_1(t_1)$其实就是根据系统的特性,产生的一个预测prediction,这个预测是独立于历史观测的,类比于最小二乘,这个预测就是那个向量$y$
mathjax 写作遇到的问题
下标经常解析不出来,需要在下标前使用空格,例如f_{k-1} 写成f _{k-1}
参考文献
Data-Driven Science and Engineering – Steven L. Brunton