学习RL(六)
TRPO,PPO和A2C
在写两个算法之后,再明确一下基于优化策略梯度的核心思想。在RL_5中推导了策略梯度是一个期望,具体形式如下:
表示在策略 下,状态的分布,这个分布是无法直接计算的。我们把 看作关于 的函数 ,那么,如果采样足够多的不同 的 ,求平均,就近似了 ,从而避免了直接计算 的问题。 - 优势函数
也无法找到准确的值,需要一个估计函数 来代替。
要注意,背后的不确定性是环境带来的,就是在既有策略
以上,回答了总结当中的问题。
TRPO:Trust Region Policy Optimization
论文整体的思路是尽量从理论上的梯度求解,通过一系列的近似,去得到一个梯度估计的近似值,用于更新策略参数。
主要贡献是:
提出一种局部估计器(local approximator),论证了把估计器减去KL差异当做目标函数
,通过最大化该函数,就可以计算得到策略的更新方向,从而使得策略不断朝向好的方向发展。 引入Trust Region的概念,限制每次策略更新的幅度,避免策略更新过大,策略变化太大,是训练不稳定的主要原因,很多工作都在维持稳定上下功夫。具体说,就是要保证最大化目标函数的同时,还要保证策略变化的KL散度在一个范围内。所以,该算法不是一个纯优化的问题,还需要满足一个约束条件。
提出重要性采样的方法,将理论上的对所有action的优势函数与策略梯度乘积加权求和,变为在一个
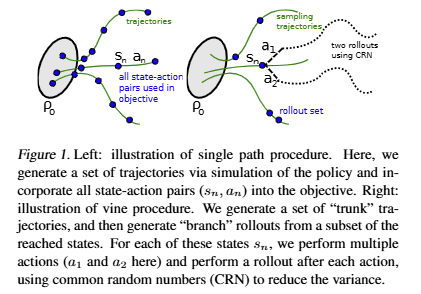
分布下的加权求和: 。在连续动作空间下, 可以取得较好效果。对于状态分布的采样,要满足 。所以,针对基于采样的估计,思路就是采用 在环境中采集一系列时间点数据,利用GAE(Generalized Advantage Estimation)里面的方法计算优势函数,然后取平均(用旧策略下的优势平均替代理论里面的对状态、动作分布的加权平均)。 下图是两种采样计算的方法:一种是针对某任何一个状态-动作对
,采集轨迹上的关于 的数据,例如优势函数等,然后平均。这点是后续PPO当中提到的rollout出来的轨迹 , 上的每一个时间点的优势相加求平均使用的方法;第二种是在每一种出现的 上,采样出若干个action分支,统计分支上的优势作为重要性采样的结果,对该结果看作是某个状态的“优势平均”,然后,再遵循 , 实际就是把这些状态下计算出来的“优势平均”再平均,我们可以想象,当一个状态分布中,某个 出现的次数越多,那么这个平均操作就更多地加入了该状态所对应的优势,从而更契合公式中的第一个期望。
论文定义一个局部估计器(local approximator)
visitation probability 替代 。这里 是说,已知 的综合收益,估计新的 的综合收益。后面对理解alg.1 有帮助。这里多讲几句,该局部估计器,对新策略 带来的reward是需要遍历所有的环境状态,根据visitation probability对一个“新的平均行动价值”求期望,“新的平均行动价值”是上面公式的第二个求和:依据旧的Advantage function和新的策略计算出“新平均行动价值”,所以,整个局部更新可以理解为原有策略的价值总和加新的策略带来的价值更新。之所以是local的,是因为如果换了策略,状态的visitation probability一定是发生变化的,但是此刻行动还没有执行,无从知道环境状态的分布发生了什么变化,只能假设变化不大,忽略,这也是论文的后面为什么一定要微调策略,而不是大动,大动的话,环境肯定会发生巨大变化,这时候,再去对局部估计器求梯度得到的更新参数,也许就是适得其反了。后面围绕如何最大化 ,就把它当做优化的目标,且需要满足一个条件,就是策略的变化评价参数 要在Trust Region 范围内。
A2C
actor-critic
结构就是构造两个函数(神经网络),actor网络输入是状态,输出是动作均值(动作空间连续);critic
网络输入是状态,输出是状态价值,用来计算
我觉得这张图非常形象生动解释了actor-critic的工作原理(来源):

在我自己写的PPO的代码里面,我还附上了一段话,算是该图的补充:
from my ppo code:
Evaluate state values according to current critic: Below story is from hackernoon: This function acts extremely as reflection: Imagine the fox called Cranberry doing the reflection. At first, it does not know the exactly values of different state-action pair (
). It has to make a prediction of such values( ) to guide itself taking next actions. But after doing several actions it stops to do a reflection: "So several steps ahead, I predicted as q, but the rewards-to-go I get is g, difference is too large, I should adjust the to a closer level of g when I have the same next time to predict!" So in Cranberry's mind there is a state-action value table to tell it the values given states. So this table is always updating. Cranberry takes the latest state-action value table to do prediction of next state-action value, but given a certain state and candidate state-action values, which action should be taken there is another table being responsible for this. Taking actions depends on the history habits and newly observed rewards, such as rewards that are never seen before. Because this fox has a family to raise, below are two restrictions:
- it does not want to easily change the history policy
- it wants to find more rewards to provide better life for its family
There should be a balance between the two. So an objective(target) combining 1 and 2 comes: penalizing big policy changes and maximizing some predicted(estimated) value(it could be
, or ) If the fox is a:
- simple policy gradient fox "Next time when I am at state s, because I know
is the largest one ,so I tune the to the biggest among those " if the expected value( ) of is not correct, it will cause less exploration and the total reward should not be the max.
- intelligent policy gradient fox "Next time when I am at state s, I should not only consider
but also consider the actual rewards after the action is taken. I should compare how different between the expected reward(Q(s,a)) of taking that action and the actual rewards. If the expected reward is high(that means high), but rewards-to-go is low, it means I overestimated the Q(s,a), in this case, I should not choose a; on the contrary, if the expected rewards is low(that means ) is low, but the rewards-to-go is high, that means I under estimated this action, I should take this action more when I am at state s in the future. So in my mind, I regard (rewards-to-go - ) as the criteria of taking actions. " -- this strategy will not only do more exploration but also keep the policy to go in the direction of at least not bad(TRPO).
Actor-Critic Framework: A concept essential for understanding the original PPO paper by Schulman et al. is the actor-critic framework [4]. Already in the 1980s, Sutton et al. argued that it is inefficient for the agent to evaluate its own actions [5]. Instead, they proposed splitting the agent into two roles: the actor, which decides actions and learns the policy π(a∣s), and the critic, which evaluates actions by estimating the state value V(s). This framework makes the algorithm versatile and balances exploration vs exploitation. The two roles can be designed using neural networks with a shared backbone. 摘自Felix Verstraete
PPO:Proximal Policy Optimization
PPO借鉴了TRPO的重要性采样思想,摆脱了策略变化不能太大的显式约束条件,而是改造目标函数,将策略变化不能太大融合到目标函数中,变为一个隐式的约束。KL计算的是整个分布的差距,PPO更简单粗暴,直接针对动作概率
另外,PPO面对的另一个问题是,在计算优势函数的时候,需要用到状态价值
TD系列,是Q-learning的基础,核心思想是基于当前状态
想要很好理解PPO具体实现细节,可以参考OpenAI的文档:

在实现中注意的点:
- 在OpenAI
Spinning Up--Key Concepts里面,提到的Stochastic
Policies, 策略神经网络(也叫做Diagonal Gaussian
Policies)返回的是动作的平均,还需要一个方差参数
,然后根据均值和方差,采样出具体的动作 。这种方式,不仅可以让策略网络输出一个连续动作空间的采样动作,还可以输出该采样动作的概率,方便生成PPO的目标函数。 - 关于衰减参数
。在优化目标函数时候,使用不衰减的奖励,但是在估计状态价值的时候,往往使用衰减的奖励。出于什么考虑,在上面的链接当中没有提到,后面找到答案会补充到这里。 