学习RL(五)
更新记录
2025-12-15:从策略下的系统演进路径
1. 为什么要有Policy Gradient
学习RL(三)当中提到,相比策略评估和策略迭代分开进行的方法,GPI已经有了进步,能够在策略评估的阶段就先把actions:
2. 什么是函数的Gradient
梯度一般是在函数自变量空间当中的一个向量(假设函数的自变量是一个向量),坐标系统是在一个垂直正交的系统中,
3. 算法推导
In this chapter we consider methods for learning the policy parameter based on the gradient of some performance measure
with respect to the policy parameter. These methods seek to maximize performance, so their updates approximate gradient ascent in :
Sutton's Book解释了为什么要计算
为了推导
,首先针对 进行梯度计算。 下面的图作为一个提纲性的指导,把如何迭代地计算某状态
的价值函数对 的梯度进行了分解。 推导过程中,因为策略
是关于 的函数,所以 , 都是关于 的函数。 使用实际应用的推导
上面的问题,我从书里找到了答案:
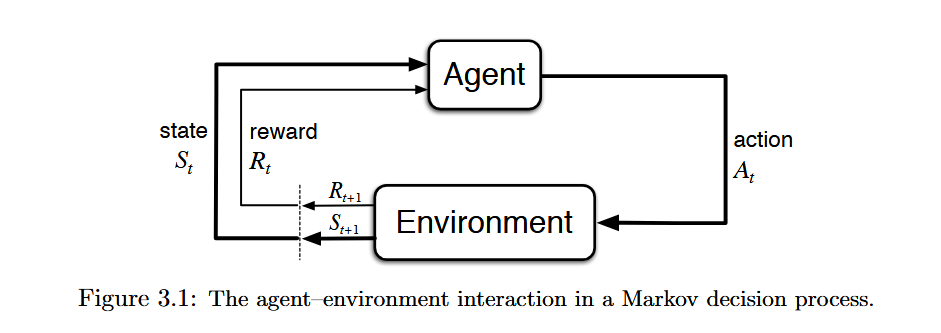
是环境的输出,在agent基于 采取行动 之后,输出了 和新的 。配合下面的图一起看。
这个事件发生的概率
继续推导,把上面对行动价值的梯度结果写入到对价值函数的梯度当中,如下图Policy Gradient的第一个公式,观察该公式是遍历了状态
之后的所有可能 。 和 都是关于状态的函数,跟action无关,最后推导的结果是 ,把action隐藏起来了。 直接对策略优化的方法,是on-policy的一种。由于
事先并不知道,在一个episode开始的时候,从某一个状态 起步,把 当作是 ,所以: 下图解释了在状态离散的情况下,
是某种状态 出现的次数,通过归一化,就可以计算该状态出现的概率,从而可以扩展到连续状态下,该状态出现的概率密度。


4. baseline的引入
先放上让人望而生畏的公式:
衡量一个策略
- 强调的是环境的反馈,但是相同状态
下,采取不同的 得到的 不同,所以,后面会牵扯进来 ,但是现在不会。 - 不需要一步直接找到
,通过求 去更新 - 先不着急展开
,先整体看: 梯度变为了一个期望。但是 还太粗糙,需要继续细化: 代表一个路径,路径拆分成一串独立的SARSA: - 单独看
(计算:策略 下形成 的概率的对数对策略参数 的梯度),顺便就把整个对数计算了: - 从而(下面的公式中,
等同于 ): - 到这里,
还不够精细,我们希望摆脱走整条轨迹之后,才可以计算期望,看看能不能每一步(step)都可以计算出来这个期望。本能地,拆开看看: 代入 ,得到
所以,得到下面的简化版本,每一行是按照
上面的推导在OpenAI Spinning Up--Don’t Let the Past Distract You里面是相同的结果。
根据状态-动作价值函数的定义State-Action-Fucntion,
2026-01-12:这里更正一下,状态-动作价值函数定义是下式,是对多个轨迹求期望的结果。(Q的真实值,像是只有上帝才知道的量,我们人类只能尽量去估计)
从时间先后看,假设

baseline
上面的问题,就开辟出了很大的想象空间。
上面的推导证明了引入baseline不会导致对梯度的估计产生偏差(bias)。重点是,为什么会减小波动,提高估计的稳定性?那就看看方差
实际上,一个期望的方差是0,因为期望是一个常数,并不会随着期望里面的变量性质变化而变化,但是实际操作,期望会有很大的变动,原因是求和后面的因素导致了不稳定。所以就跨过严格的数学定义,直接看求和的实际变动。
chapter:
Understanding the Baseline (下面的公式引自链接文章!)公式中
向实际应用考虑
Advantage Function
State-Action-Fucntion里面:
这篇论文generalized advantage estimation(GAE)详细介绍了如何更好地通过估计Advantage Function 来实现策略梯度。
Quote from GAE:
The choice
yields almost the lowest possible variance, though in practice, the advantage function is not known and must be estimated. This statement can be intuitively justified by the following interpretation of the policy gradient: that a step in the policy gradient direction should increase the probability of better-than-average actions and decrease the probability of worse-than-average actions. The advantage function, by it’s definition , measures whether or not the action is better or worse than the policy’s default behavior. Hence, we should choose to be the advantage function , so that the gradient term points in the direction of increased if and only if . See Greensmith et al. (2004) for a more rigorous analysis of the variance of policy gradient estimators and the effect of using a baseline.