卡尔曼滤波器学习笔记(二):随机过程和线性卡尔曼滤波器
随机过程的模型建立
一般地,我们研究的随机过程是一个动态的系统(Dynamical Systems).
其中,
为了简化我们对系统的建模,首先把时间和系统参数对系统迭代的影响忽略掉,简化上面的等式:
(
上面的等式仍然不是很理想,因为经常性的,
那么,需要对(
(
状态转移方程
(
(
非线性的系统状态转移矩阵是根据系统的雅可比矩阵来确定的,每次迭代都会变。后续需要确认是不是这样。
到目前为止,根据系统的物理定律我们在没有测量的状态下得到系统状态是如何迭代的,但是需要注意(
随机过程的贝叶斯后验概率分布推导
根据第一讲贝叶斯滤波的基本思路,系统迭代的过程中,需要有测量数据做融合,从概率论角度讲就是测量数据
在推导之前,需要非常明确这几条:
- 状态向量迭代的过程虽然是离散的,例如
, 时刻的状态,但是在某一时刻的取值仍然是连续的随机变量,我们在第一篇里面得到的结论仍然适用于某一时刻的情况。 - 在不同的时刻下,先验、后验分布都在变化,先验分布变化是因为系统因为物理、化学等规律随之前的状态产生了新的变化 -- 就是由状态转移方程描述的。
后面的公式当中,
状态转移的概率分布推导
第一个需要推导的是如何根据
(
对
到这里很容易迷茫不知道怎么办,看
令
继续推导得到:
这里,条件概率变为了当
(
观察(
概率分布函数是概率密度函数的原函数,根据微积分第一基本定理,对
当
测量更新的概率分布推导
这里首先需要给定测量出来的向量作为随机变量
再次列出来连续随机变量的贝叶斯公式:
测量向量
后验概率分布如下:
需要利用(
首先是似然概率:
条件概率当中的条件可以拿来参与计算,(
条件概率的条件
然后是边缘概率。
到这里,我最开始对于为什么需要把分母的那个边缘概率展开为全概率是不理解的,它其实就是一个不为零的常量,直接放在那里不是就可以了么?
在 Kalman and Bayes Filters in Python3.12
章节讲到了这个量叫做evidence,就是不考虑当前状态在哪里的情况下,测量值出现
那么问题又来了,我们怎么寻找那个全概率的“基底”呢?就是上一篇文章中说的
令
得到:
因为在实际计算的过程中,预测步骤得到的
卡尔曼滤波器
引入期望的几何意义
(
Kalman在1960年发表的论文当中,首先论证了如何最小化估计和真实值之差在给定测量值条件下的期望,解就是状态在测量条件下分布的期望。
(
论文中还讲了正交投影,把测量空间内的随机变量分解为若干个单位正交的随机变量的线性组合,定义随机变量正交需要满足乘法期望为零。所以,任意随机变量可以分解为两部分:一部分属于测量空间,一部分属于正交于测量空间。
测量空间的表示
(
正交空间的表示
论文中证明了在正交空间内的任意随机变量,都和测量空间内的随机变量正交,下面的符号代表了正交空间内的随机变量:
状态变量的最优估计就是向测量空间做正交投影得到的新的随机变量
论文中证明了这一点。在阅读论文的过程中,我发现,推导过程和模型很类似于最小二乘法在向量空间中的推导,所以下面的描述是对照最小二乘和随机变量的最优估计来进行。
在我之前的一篇文章《投影矩阵和最小二乘》中,已知空间当中的一些点,如何找到一条直线使得这条直线到每一个已知点的距离最小,这个问题和现在的随机变量估计问题有很深的类似关系。
- 给定的已知点就是这里的测量,而且不同时刻
的测量 这个随机变量才对应于最小二乘里面的点 - 最小化一个目标函数,在最小二乘当中,最小化的是误差绝对值的求和,在这里最小化的是估计出来的随机变量
和真实值 的差的损失函数的期望,文中提到最常见的损失函数是二次方的 - 最小二乘当中,为了求出那条直线,需要确定两个参数
和 ,在二维空间正好参数的确定和描述一个点 所需要的维度相同,矩阵 的列向量所形成的空间对应的是这里测量空间 - 如果随机变量
、 期望都是0,这里最小化损失函数的期望所对应的最优估计(Optimal Estimation)就是当前的随机变量 向测量空间做投影得到 ,对应于最小二乘中使用投影矩阵对向量 左乘得到投影向量 - 得到了投影之后的随机变量
通过( )就可以得到对应的参数。
论文当中的演进思路
Optimal Estimates: 给定了一组测量值,如何最优估计出来带有噪声的测量值所测量的状态向量?Wiener指出状态估计问题就是需要使用概率理论和统计的方法来解决。论文当中的定理1,说的是对状态向量的最优估计(最优的意义是把估计量和实际量做差当作一个随机变量,然后对该变量求loss 一般是
)等价于状态向量在出现测量的条件下的期望。就是说,首先,我们需要搞清楚这个条件概率的分布,其次,把这个分布的期望当作最终的估计量--符合我们对事情的认知,因为我们经常通过求平均数来获取一个数据更加准确的估计。求期望,其实就是统计平均。 Orthognal Projection: 讲的是给定一组测量值
且这些测量向量的元素一一对应状态向量中的元素,且 和 是期望为0的正态分布随机变量,在这些测量的条件下的最优估计是状态正交投影到测量空间得到的投影向量。但是到目前,我们仅仅是知道投影向量一定是测量值的线性组合(因为对那些basis-- 做投影得到的系数和对具体的测量值做投影得到系数,虽然具体的系数不一样,但是组合起来都代表同一个向量,具有等效性,而且测量值是直接得到的数据,为了方便,那么就直接使用测量值的线性组合来取代basis的线性组合),但是不知道具体的系数。 因为卡尔曼滤波以实现简单著名,一个重要的原因是它不需要记录历史的所有观测就可以做最优估计,但是到目前为止,我们还不知道怎么迭代性地使用上面的结论。 Models For Random Processes: 讲的是对系统进行建模,最理想的情况是首先定义了一个时间原点,然后根据当前时间作为输入给出我们关心的系统输出和时间的数学表达式。这样的方法在实际应用当中不方便,人们更多关注的是基于现在的已知情况,求出当前情况下的系统输出是什么样子(状态转移方程)或者系统变化了多少(一阶微分方程),不管是前面的哪种,都属于一个迭代的描述,从而有了有一阶的微分方程,如果系统是线性的,可以把微分方程写成状态转移方程。但是,尽管我们可以得到状态转移方程,在实际应用当中,无法忽视系统迭代过程中噪声模型,人们也不可能列举所有可能的输入下系统输出的分布情况,但是人们可以统一做一组实验,就是在单位阶跃的输入下,系统随着时间如何变化,或者在均值为0的高斯扰动下,系统产生的输出的不确定度,这个不确定度使用了
来表示。需要指出的是,在实际应用中,我们的输入信号已经具有了一定的不确定度,就是 ,那么经过系统之后,输出的不确定度其实是变大的,也就是论文中公式(24)所要表达的内容。 Solution Of the Wiener problem: 讲的是从系统迭代的角度,在有状态转移方程、过程噪声协方差矩阵、测量向量和测量噪声协方差矩阵情况下,如何求解系统状态的最优估计。99%的情况下,新得到的测量值一定是携带了新的有用信息,从数学的角度来看,就是这个
一定不在原有的 空间内,如果系统运转仍旧保持连续的话,大概率主要部分仍然在 内,少部分在 正交空间内。方法是把 状态向量(经过当前次系统的输出)对 的条件期望改写为对 和 (新增测量向量与 形成的正交空间)的条件期望之和(因为两个空间正交,且两个空间合起来组成的manifold和 代表的manifold是完全一样的。那么对 的条件期望就等于分别对这两个正交空间求条件期望再相加),根据论文之前的所描述的,最后得到一个 的矩阵 就得到了卡尔曼增益矩阵。这个矩阵本质上是把新增的这个正交空间内的有用信息加进来形成在全观测下的最优估计。但是到这里,如何计算这个增益矩阵是不知道的,后面根据过程噪声和测量噪声推导卡尔曼增益。 这一步就是需要计算出卡尔曼增益矩阵的具体表达式。因为卡尔曼增益是
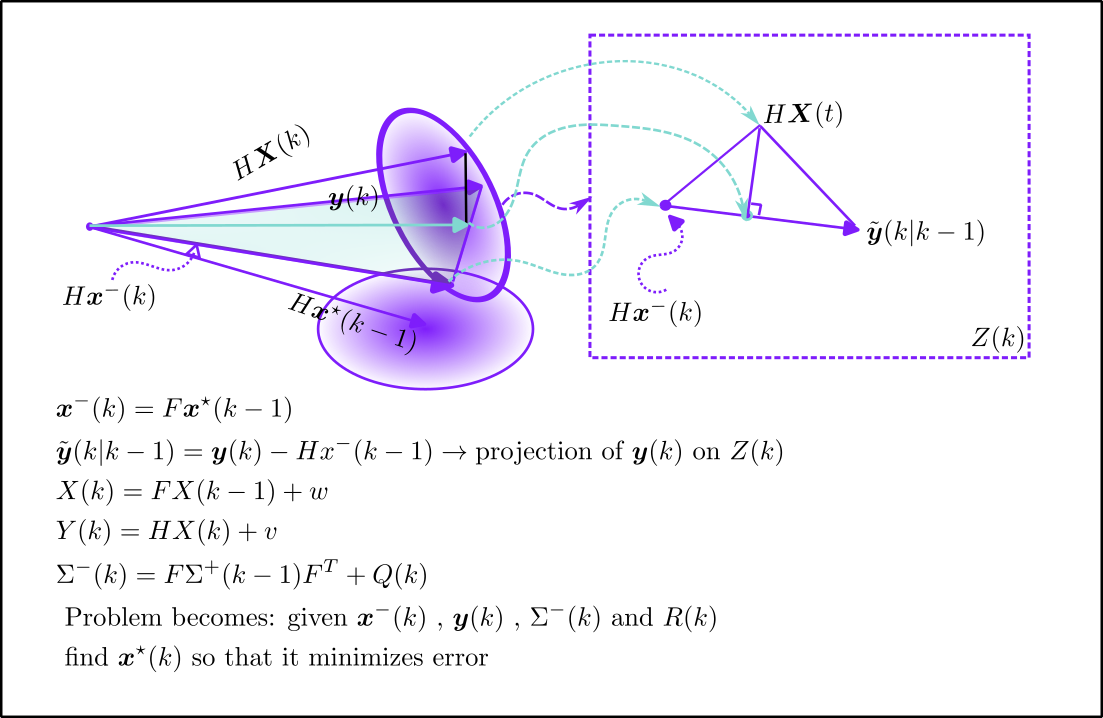
空间内的向量的线性组合系数,公式(18)表述的最优估计取决于预测和测量两个过程的准确性。直觉上,如果过程噪声小,测量噪声大,那么,最优估计就更接近预测,反之,更接近于测量。 论文中公式(25)卡尔曼增益为什么要那样计算我不明所以,但是我觉得作者心里有一个直观的图形指导他如何推导的。 有必要把前面说的两个噪声画出来,形象理解。经过参考另外一篇论文,卡尔曼滤波的几何解释,作者把状态分为两部分,一部分是观测可以直接测量到的,另一部分是观测无法直接测量的。
我理解的计算过程如下图:图中灰色椭圆代表了新的测量引入的额外信息
首先需要明确的是测量误差和经过预测的可观测部分和测量值之间的误差是不同的。
2025-06-04
Geometric
illustration of the Kalman filter gain and covariance update
algorithms - 下图左侧,
原始论文当中,其实并没有提到从几何的角度理解,但是重点强调了垂直于
空间的 空间:下图右侧的虚线矩形框。 最优估计一定要落在
上面吗?答案是一定的。首先,基于系统和基于测量,我们得到的是两个具体的向量,这两个向量一定是带噪声的,那么,我们很清楚地知道:真实的状态一定是悬在这两个向量之外的某个地方,虽然不确定,但是根据 和 ,原始论文推导到公式(18)的时候,很明确地得出:新的测量带来新的那部分空间,对于状态的更新部分就是 ,那么,两个空间(平面)相交所形成的交线就是量测在新空间的更新部分 问题变为如何在已知一个点和一条线段的前提下,求出点到线段的最短距离--这个距离体现的就是卡尔曼估计的状态更新误差
适当理解右图的三角形:当三角形左边直角边变短(系统模型更精确):卡尔曼估计偏向系统的预测;当三角形右边直角边变短(测量噪声更小):卡尔曼估计偏向测量。
卡尔曼增益是从三角形左下顶点到垂足的线段和整个斜边的比例。
续2023-12-08:
可以用简单的几何关系来推导一下:
推出:
不可观测部分:
推出:
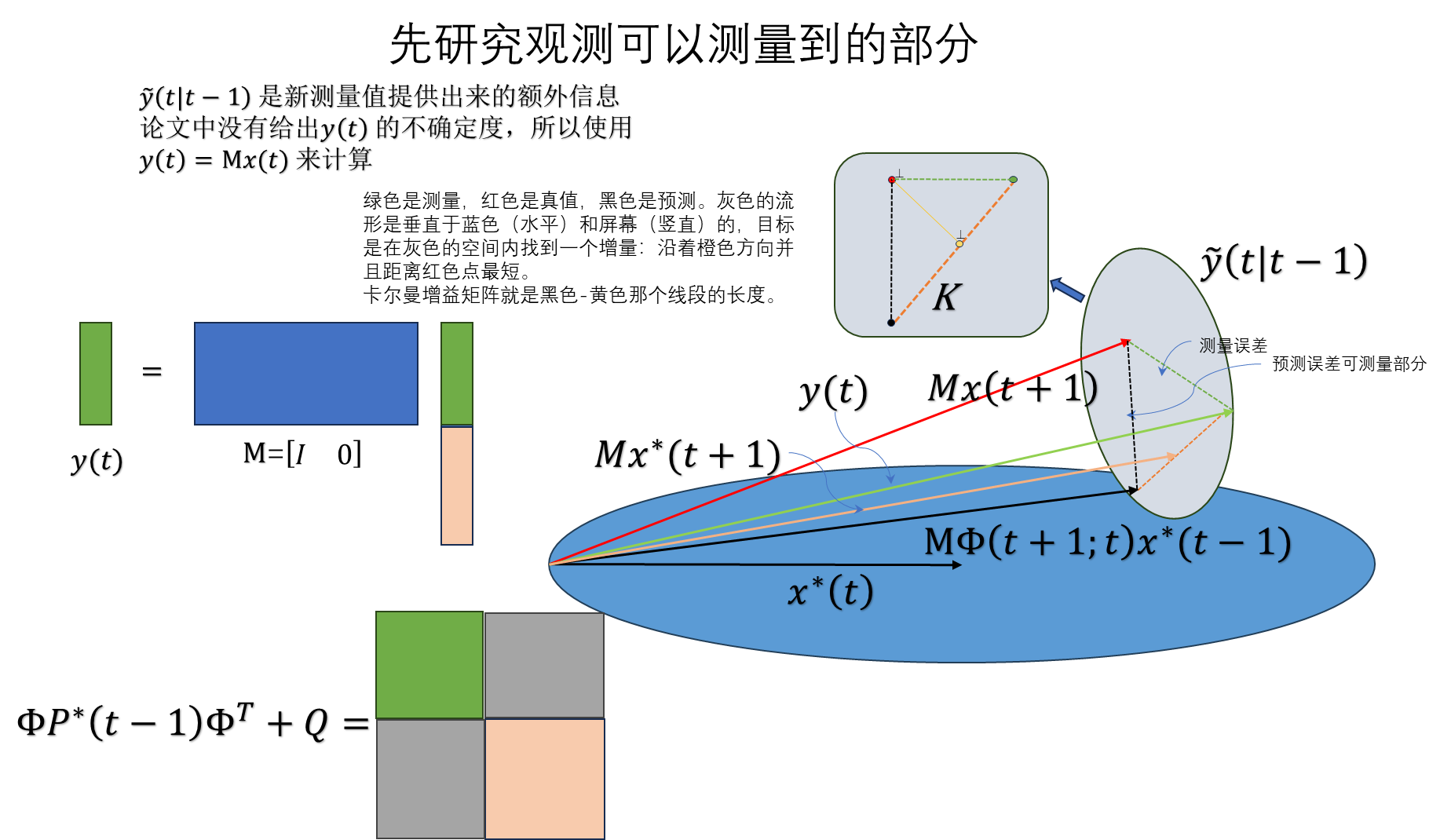
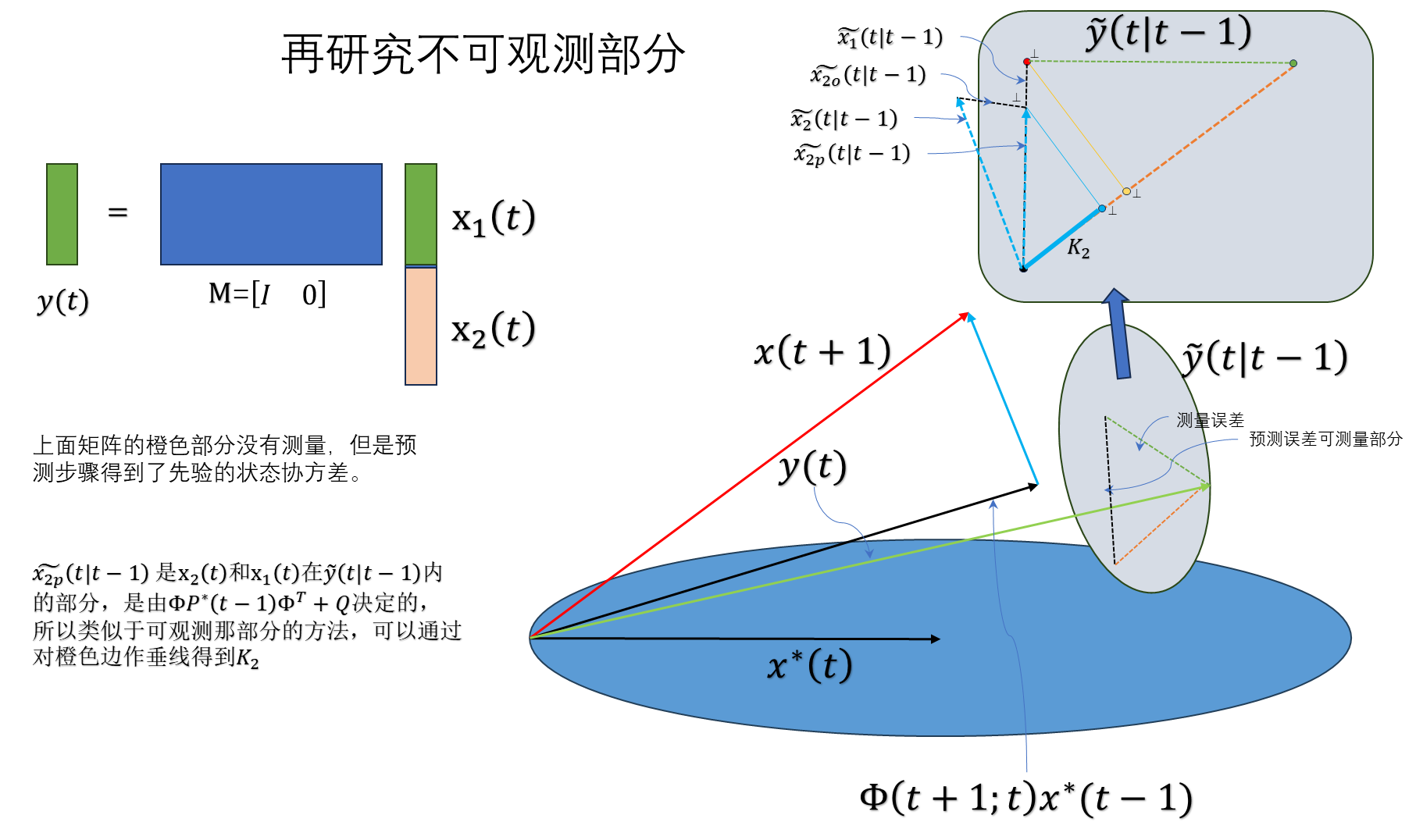
有了直观的几何理解,后面的具体推导部分,就比较容易理解和建立对应关系了。
具体的推导过程
就是假设随机变量的分布是高斯的,也叫做正态分布,这个分布有如下的特性:
- 使用
表示期望, 表示方差,两个参数可以完全描述一个高斯分布 - 假设过程噪声
,测量噪声 ,两个随机变量期望均为0,协方差矩阵为 和
所以过程噪声的概率密度函数写为:
测量噪声的概率密度函数写为:
由于我们需要从第
次开始迭代推导,需要首先明确的是状态变量 符合什么样的分布?根据论文的描述,在两个前提条件下: (1)随机变量
和 是高斯的,具体说来就是( )中的 是期望为0,协方差矩阵为 的高斯分布,( )中的 是期望为0,协方差矩阵为 的高斯分布。 (2)最优估计当中的损失函数定义为
,第 次的最优估计是就是 所在空间的基的线性组合,因为这个空间内的基是满足高斯的,所以高斯的线性组合仍然为高斯的: 根据(
)推导先验概率密度:
高斯分布概率密度函数代入:
上面的推导得到结果:
- 根据(
)推导后验概率密度:
(
- 卡尔曼滤波的五个公式。
(
卡尔曼滤波和最小二乘的关系
2025-5-29
投影矩阵和最小二乘
-
最小二乘解决的是已知空间中有很多点,如何找到一条直线,能够保证这条直线到给定的所有点的距离最短,具体问题的形成过程参考上面的链接。
-
卡尔曼滤波解决的是:已知历史上很多的观测点,如何得到待估计的状态的最合理的值,这个最合理,Kalman定义出一个loss
function,就是实际上的状态(Ground Truth)
- 2)状态估计
是 的某种函数 - 3)背后有一个隐含的东西是:我们手头上拿到的观测其实代表了一个空间(这是客观存在的根本信息,比观测本身要有更好的质量,因为可以通过一些正交基
来表征,其实这些基也是晃晃悠悠的,但是好消息是它们是正交的: ),我在这里把这个空间叫做量测空间。 - 4)最小二乘里面最小化的是那个
, ,但是卡尔曼先生希望最小化的是误差函数的期望 ,更准确地说应该是一个条件概率函数的期望 - 5)卡尔曼先生用图形化的方法(其实就是最小二乘的模型),空间当中给定任意一个向量,其实就是待估计的状态
的一个具体向量 ,它是一个随机变量,也是一个向量, 不太可能完全存在于刚才提到的那个空间当中,但是!它的一部分存在,那一部分可以是很少,可以是很多,最优的估计(使得 最小的估计)就是把 投影到量测空间,让 最大程度地出现在量测空间。相比于最小二乘的确定性(Deterministic),卡尔曼滤波针对不确定性所做的投影操作就是求待估计量对观测的条件概率的期望,最后落实到地面就是拿着具体活生生的向量 做投影,投影得到的那个 就是本次量测更新,人们就可以使用它!!!!原论的文当中公式(5) 。 - 6)上面的描述过程,其实大部分是飘在天上~
- 7)如果我们联系上要研究的系统,
其实就是根据系统的特性,产生的一个预测prediction,这个预测是独立于历史观测的,类比于最小二乘,这个预测就是那个向量
mathjax 写作遇到的问题
下标经常解析不出来,需要在下标前使用空格,例如f_{k-1}
写成f _{k-1}
参考文献
Data-Driven Science and Engineering -- Steven L. Brunton